Better ProgrammerWhere best programming happens2017-07-04T19:34:24.000Zhttp://blog.kiyanpro.com/FreeTymeKiyanFreeTymeSunKiyan@gmail.comHexoConcepts in Online Ads Industryhttp://blog.kiyanpro.com/2016/11/27/ad-concepts/2016-11-27T08:00:00.000Z2017-07-04T19:34:24.000ZI’ve been in Yahoo for almost one and a half year and dedicated myself in the Ads Targeting team. During my time here, I found that there are many domain specific concepts and abbreviations that everybody talks about and presume everyone else already knows. Of course, every time I will ask about those terms later. Otherwise I never know when they will show up later and make me confused again. But instead of ask each of them every time, I decide to do a “batch job” today and learn the common terms together. Here is my note.
Terms
Targeting
Delivering ads to a pre-selected audience based on various attributes, such as geography, demographics, psychographics, web browsing behavior and past purchases.
Targeted advertising has proven to be beneficial for the advertiser as it is cost efficient because it is focused on certain traits. The consumers who are likely to have a strong preference will receive the message instead of those who have no interest and whose preferences do not match a product’s attribute. This eliminates some wastage.
Retargeting
Serving ads to people who have previously visited your website.
Retargeting is where advertising use behavioral targeting to produce ads that follow you after you have looked or purchased are particular item.
Examples of this is store catalogs, where after purchase they subscribe you to their email system hoping that they draw your attention to items for continuous purchases.
Retargeting is a very effective process, by analyzing consumers activities with the brand they can address their consumers behaviour appropriately.
Audience
The total number of people that have been exposed to or could possibly be exposed to an ad during any specific time period.
Reach
The total number of people who see your message. One person who is served your ad five times and clicks on it once yields a reach of 1, 5 impressions, and a clickthrough rate of 20%.
Impression
The number of times an ad has been served, regardless of whether the user has actually seen or interacted with the ad in any way.
Click
The action taken when a user interacts with an ad by either clicking on it with their mouse or by pressing enter on their keyboard.
Action/Conversion
When launching a campaign, advertisers select a specific action or set of actions they want audiences to take. Each time a member of the audience takes this action, it is counted as a conversion. For example, the user download the APP or buy the product after served with the ad.
CTR
Clickthrough rate, expressed as a percentage of total impressions, shows how often people who are served an ad end up clicking on it.
An ad’s CTR is calculated by dividing the number of clicks an ad received by the number of times it’s been served, then converting that into a percentage. For example, if an ad received 5 clicks and was shown 1000 times, the CTR is 0.5%. The higher the CTR on an ad, the better it’s performing.
CTA
Call to Action (CTA): A phrase included within an ad, or a graphic element such as a button, which invites the audience to take a certain action.
Examples include phrases such as “Click to Read More”, “Download Your Free eBook Now”, or “Click Here”.
Conversion Pixel
A 1×1 image pixel placed on a web page (such as a thank-you page) which is triggered whenever a conversion occurs. Usually transparent.
CVR/AR
Conversion/Action rate, expressed as a percentage, a conversion rate can be calculated in two ways:
The first is by the taking the number of users who completed the conversion and dividing it by the total number of impressions served. The second, more common way, is by taking the number of users who completed the conversion and dividing it by the total number of users who clicked on the ad.
View Through
Used to measure a consumer’s behavior after they’ve been served an ad. If the “view through” window is set to 90 days, the consumer’s relevant actions within that time period can be attributed to the ad.
ROI
Return on investment is “the bottom line” on how successful an ad or campaign was in terms of what the returns (generally sales revenue) were for the money invested.
CPA
Cost per Acquisition: The cost of acquiring one customer. Typically calculated by dividing the total amount spent on an advertising campaign by the number of customers acquired through that campaign.
CPC
Cost per Click: How much an advertiser pays, on average, for each ad click. CPC is calculated by dividing the total amount spent on a campaign by the number of clicks generated.
CPL
Cost per Lead: How much an advertiser pays, on average, for each ad click that results in a lead conversion. CPL is calculated by dividing the total amount spent on a campaign by the number of leads generated.
CPM
Cost per Thousand: Metric that shows how much it costs to serve 1,000 ad impressions. Also used as a standard measure for buying display ads, as inventory is generally sold on a CPM basis.
PPC
Pay per Click: Pricing model where advertisers pay vendors or publishers based on the number of clicks received in a campaign.
PPL
Pay-per-lead: In pay-per-lead advertising, the advertiser pays for each sales lead generated. For example, an advertiser might pay for every visitor that clicked on a site and then filled out a form.
PPS
Pay-per-sale: Pay-per-sale is not customarily used for ad buys. It is, however, the customary way to pay Web sites that participate in affiliate programs , such as those of Amazon.com and Beyond.com.
PPV
Pay-per-view: Since this is the prevalent type of ad buying arrangement at larger Web sites, this term tends to be used only when comparing this most prevalent method with pay-per-click and other methods.
Ad Serving
The delivery of an ad from a web server to the end user’s device, where the ads are displayed on a browser or an application.
Summary
This “batch learning” is actually very efficient and interesting. I actually learned more terms then I had expected. Hopefully next time these terms won’t be of that much trouble to me. I will also keep this post updated whenever there are new terms emerge.
]]>
<p>I’ve been in Yahoo for almost one and a half year and dedicated myself in the Ads Targeting team. During my time here, I found that there
Memory Usage Estimation in Javahttp://blog.kiyanpro.com/2016/10/07/system_design/memory-usage-estimation-in-java/2016-10-08T04:06:23.000Z2017-07-04T19:34:24.000ZI mentioned in the previous post that memory usage estimation is also very important when it comes to evaluate a design. And I was impressed deeply by my two former tech leads when they do a quick estimate of my proposal on a small piece of paper, or even with just a mental calculation. Now it is the time for me to grasp the gist behind.
Premises
The actual memory calculation can be very complicated in terms of implementation, synchronization, and etc. Take Java as an example. Java is implemented on a very wide range of computational devices, and memory consumption is implementation-dependent. So there is no guarantee that the memory usage is same for all of those devices. And If an object’s synchronization lock is contented, or the object is under garbage collection, the usage would not be the same.
So what we are going to discuss are based on these following premises:
Memory usage in general conditions
For Java only
Heap memory, not stack memory
64-bit machine, which means that 8 bytes are needed to represent addresses
Many older machines use a 32-bit architecture. I also read some older posts based on it. In this situation, the only difference is that each machine address is just 4 bytes.
Baiscs
Here comes the very basic idea. Almost the same as time cost estimation:
Know typical memory usage in Java
Decompose a design into these basic usages
This post mainly focuses on the typical memory usage in Java and will not cover any decomposition, because once we have the design, it would be fairly simple for us to come up with the count of each usage.
Primitives
First and foremost, let us take a look at the memory requirements for primitive types.
Table 1.1 Typical Memory Requirements for Java Primitive Types
type
bytes
boolean
1
byte
1
char
2
short
2
int
4
float
4
long
8
double
8
A problem one may have is that why boolean consumes 1 byte, since the information can be expressed well with a single bit. This is because computers access memory one byte at a time. It would be awkward if we had to cope with sub-byte offsets for certain fields, and it would require extra logic to read/write individual bits at a given position rather than just the whole byte each time the boolean was accessed.
Why is int 4 bytes? Since the Java int data type is the set of integer values between -2,147,483,648 and 2,147,483,647(2^31), a grand total of 2^32 different values, typical Java implementations use 32 bits to represent int values.
If we know the amount of memory available, we can calculate limitations from these values. Just a simple division. For example, if we have 1GB of memory on our computer (1G = 10^9 or 2^30), we cannot put more than about 2^30 / 4 = 2^28 = 2^8 * 2^20 = 256 million int values or 128 million double values in memory at any time.
Objects
In general, the heap memory used by a Java object consists of:
an object header, consisting of a few bytes of “housekeeping” information
memory for primitive fields
memory for reference fields
padding
To determine the memory usage of an object, we add the amount of memory used by those cases above. Let us figure out each part of them.
The first one is the header. What is the “housekeeping” information? It includes a reference to the object’s class, garbage collection information, and synchronization information. Typically 16 bytes.
We already mentioned the memory consumption for each primitive fields. The total memory is a sum of each primitive field. E.g, if an object contains only two primitive fields, which are int, they will cost 8 bytes.
Reference fields are actually pointers to other objects. This “pointer” is just a memory address, thus uses 8 bytes of memory.
What is padding then? The memory usage is padded to be a multiple of 8 bytes for a 64-bit machine. We can take it as a few “wasted” unused bytes after the object data, to make every object start at an address that is a convenient multiple of bytes and reduce the number of bits required to represent a pointer to an object.
Examples
How many bytes does an Integer object use? We know that Integer is a wrapper of int and that is its only primitive field, 4 bytes. Then as an object there will be a header of 16 bytes. So 20 bytes in total? No. Do not forget about the padding. We still need a few bytes to reach the closest multiple of 8, which is 24. So 4 bytes of padding should be added and the result is:
16 bytes of overhead + 4 bytes int + 4 bytes padding = 24 bytes
How about a Date object then? Similarly, the result consists of an overhead, the three int fields (day, month, year), and a padding.
16 bytes of overhead + 3 * 4 bytes int + 4 bytes padding = 32 bytes
How about the Counter class below which also has a reference to a String?
1
2
3
4
classCounter{
String s;
int c;
}
According to our general rule, the result now not only contains an overhead and an int field, but a reference to another object as well. That is:
16 bytes of overhead + 4 bytes int + 8 bytes of reference + 4 bytes padding = 32 bytes
When we account for the memory for a reference, we account separately for the memory for the object itself, so this total does not count the memory for the String value.
Linked lists
A speical case is when there is an inner class in the object. A nested non-static (inner) class requires an extra 8 bytes of overhead for a reference to the enclosing instance.
For example, suppose we have a stack with N integers built with a linked-list representation like below:
private Node first; // top of stack (most recently added node)
privateint N; // number of items
privateclassNode{ // nested class to define nodes
Integer i;
Node next;
}
...
}
How many bytes does it use? In addition to the usual 16 bytes for object overhead for Stack, it also has 8 bytes for its reference to Node, 4 for the int N, 4 for padding. That is 32 bytes. And for each entry, it contains a Node and an Integer. A Node class takes 40 bytes, including 16 bytes overhead, 8 bytes to Integer i, 8 bytes to the next Node, and an extra 8 bytes overhead to the enclosing instance (Integer i). Plus an Integer takes 24 bytes. So it costs 64 bytes for each entry. The grand total is 32 + 64N bytes.
Arrays
Now we already know how to estimate the memory usage of a single object, what if we put these object together in an array or a collection?
First we need to know the how arrays are implemented in Java. Arrays in Java are implemented as objects, with some extra overhead for the length. So an array itself takes:
Besides, the memory needed to store the values in the array should be included. It is different in terms of the types of the value.
Array of Primitives
For primitive types all we need to do is multiplying the length of the array by the bytes used by that type. For example, an array of N int values uses 24 + 4N bytes (then rounded up to be a multiple of 8), and an array of N double values uses 24 + 8N bytes (no padding needed, already a multiple of 8).
Array of Objects
An array of objects is an array of references to the objects, so we also need to add the space for the references to the space required for the objects. For instance, an array of N Date objects uses 24 bytes (array overhead) plus 8N bytes (references) plus 32 bytes for each object, for a grand total of 24 + 40N bytes.
Multi-dimensional Array
Multi-dimensional array is a little more complicated. When we estimate, we should decompose the usage into two parts: 1) the outer array 2) the inner array or the values.
Let us start with a two-dimensional array first. What is the implementation? A two-dimensional array is an array of arrays and each array is an object.
Suppose we have an M-by-N array of double values. The outer array uses 24 bytes overhead plus 8M bytes references to the each array object. Then for the M inner arrays, each of them has 24 bytes overhead plus N times 8 bytes for the N double values. The grand total is:
What if the array entries are objects? First, we replace the cost of double values with the cost of references to the objects, which happens to be the same and leads to a total of 8MN + 32M + 24 ~ 8MN bytes for the array of arrays filled with references to objects. Then we add up the memory for the objects themselves.
For arrays of more than two dimensions, the above logic repeats: each row of the “outer” array is now an array of references to a further array, which contains the actual primitive data (or references if it is an object array).
Strings
We put String after array as we know the implementation of String contains an array of char primitives. The standard String representation (used in Java 7 and after) has two instance variables: a reference to a character array value[] that stores the sequence of characters and an int value hash that stores a hash code that saves recomputation in certain circumstances.
How many bytes does a String of length N use then? For the String object itself, it consists of an overhead, a reference to the array, an int field, and a padding. In total:
Besides that, we need to include the memory used by the array, which is an array of N characters. It contains a 24 bytes overhead and N * 2 bytes char primitives. So the grand total is:
32 bytes + (24 + 2N) bytes = 56 + 2N bytes
The implementation was different in Java 6 and earlier versions. An alternate String representation maintains two extra int instance variables, offset and count, and represents the sequence of characters value[offset] through value[offset + count - 1]. Now, a String of length N typically uses 40 bytes for the String object plus 24 + 2N bytes (for the character array) for a total of 64 + 2N bytes. This representation saves memory when extracting substrings because two String objects can share the same underlying character array.
Summary
In this post, we introduced the step-by-step method to estimate memory usage in Java. The first thing is to know the some basic numbers for simple situations like primitive types and single object. Then we dive deeper into more complex cases, such as inner classes and arrays. Building on that, we turn to a widely used special object, String, to estimate its usage.
Still, we can do this fairly quick on the back of an envelope or on a piece of small post-it paper. And memory usage estimation is actually easier than time cost estimation, primarily because not as many program statements are involved (just declarations) and because the analysis reduces complex objects to the primitive types, whose memory usage is well-defined and simple to understand: we can count up the number of variables and weight them by the number of bytes according to their type.
Of course, for most of the times, we care more about time cost and ignore memory usage. But, again, for a performance critical system, we need to make sure both time and memory consumption are acceptable for now and the future. Memory is cheap nowadays, but it is not free. In fact, none of the resources are free. Hope that we can grasp the estimation methods of these resources and make the best use of them.
References
Chapter 1.4 Analysis of Algorithms, Algorithms, 4th Edition
]]>
<p>I mentioned in the previous post that memory usage estimation is also very important when it comes to evaluate a design. And I was impres
Back of the Envelope Calculationhttp://blog.kiyanpro.com/2016/09/21/system_design/back-of-the-envelope-calculation/2016-09-22T02:48:48.000Z2017-07-04T19:34:24.000ZSo, I continued the journey on learning about System Design and found another very good resource. It is a talk by Jeff Dean at Stanford named Software Engineering Advice from Building Large-Scale Distributed Systems[1]. In this talk, Jeff Dean shared the lessons and tips learned from his various kinds of experience.
One important skill he pointed out in the talk is the ability to estimate performance of a system design, in terms of time cost. Why is it important? Because this skill actually allows you to choose the best solution without building it.
Some fundamental knowledge is required to grasp this method:
Time costs for some basic steps
Decomposition of a design
Time Cost
Jeff provided a brief table for the costs. This table is lucid overall but some rows in it might be unclear. I will show the table first and try to explain those rows.
Time Cost Table
Table 1.1 Numbers Everyone Should Know
Basic Step
Time
L1 cache reference
0.5ns
Branch mispredict
5ns
L2 cache reference
7ns
Mutex lock/unlock
100ns
Main memory reference
100ns
Compress 1K bytes with Zippy
10,000ns
Send 2K bytes over 1Gbps network
20,000ns
Read 1 MB sequentially from memory
250,000ns
Round trip within same datacenter
500,000ns
Disk seek
10,000,000ns
Read 1 MB sequentially from network
10,000,000ns
Read 1 MB sequentially from disk
30,000,000ns
Send packet CA->Netherlands->CA
150,000,000ns
Explanation
We keep speaking and hearing all the time that L1 cache is the fastest, then the L2 cache, then the main memory, and finally the disk. We always want to cache data in memory instead of disk. Here in the table we can find data support for this point. In addition to these numbers, we should also concern the time costs of L3 cache(12.9 ns), Solid-state drive(50-150 μs), and network(can vary based on different network environment)[2].
As main memory becomes larger and larger nowadays, a clear trend in system design is to put performance significant data in memory rather than on disk. For example, in Elasticsearch, I use in-memory aggregation to boost the query process and avoid disk seeks. As a result, the system can return 1000 hits in 10 to 20ms, which is almost 100x faster than a normal query(around 1 sec). Another example would be the widely use of in-memory cache, such as Memcached and Redis, which can save us enormous amount of disk hits from read requests send to DB.
What is Branch mispredict? Here is the explanation from Wikipedia[3]:
Branch misprediction occurs when a central processing unit (CPU) mispredicts the next instruction to process in branch prediction, which is aimed at speeding up execution.
During the execution of certain programs there are places where the program execution flow can continue in several ways. These are called branches, or conditional jumps. The CPU also uses a pipeline which allows several instructions to be processed at the same time. When the code for a conditional jump is read we do not yet know the next instruction to execute and insert into the execution pipeline. This is where branch prediction comes in. Branch prediction guesses the next instruction to execute and inserts the next assumed instruction to the pipeline. Guessing wrong is called branch misprediction. The partially processed instructions in the pipeline after the branch have to be discarded and the pipeline has to start over at the correct branch when a branch misprediction is detected. This slows down the program execution.
We will show an example in the next section that relates to branch mispredict.
What is Mutex lock/unlock? I found some words from Webopedia[4] that explains it well:
Mutex is short for mutual exclusion object. In computer programming, a mutex is a program object that allows multiple program threads to share the same resource, such as file access, but not simultaneously. When a program is started, a mutex is created with a unique name. After this stage, any thread that needs the resource must lock the mutex from other threads while it is using the resource. The mutex is set to unlock when the data is no longer needed or the routine is finished.
Wikipedia also throws light on mutex’s significance[5]:
Mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions; it is the requirement that one thread of execution never enter its critical section at the same time that another, concurrent thread of execution enters its own critical section.
So knowing how long it takes to do mutex lock/unlock, we are able to estimate the time cost for concurrent designs.
What is Zippy? Zippy, or Snappy, is actually a fast compressor/decompressor open sourced by Google. Here is what I found on Snappy Github page[6]:
It aims for very high speeds and reasonable compression. Compared to the fastest mode of zlib, Snappy is an order of magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100% bigger.
In situations where our design consists of data compression, we can use the number here to help.
“Send 2K bytes over 1Gbps network” is easy. Just do the math. 2 10^3 8 bit / (1 10^9) bit/s = 16 10^(-6) s ≈ 2 * 10^4 ns.
Read 1 MB sequentially from memory/network/dist. Obviously, with the time costs we know that reading from memory is the fastest. When calculate time cost, I think it is more useful to know how many bytes per second instead, which are 4000 MB/s, 100 MB/s, and 30 MB/s, respectively.
Round trip within same datacenter. It is good to know that even the same data center has time cost. Latency in the data center matters when it comes to performance critical systems. That means even our machines in the same cluster access each other can take time. For instance, if we’re using a distributed in-memory key/value store, we need to fetch data from another machine in the cluster. That would be a few 500,000ns (or 0.5ms) round-trips in the same datacenter[7].
Send packet CA->Netherlands->CA, 150ms. That is a round trip between the west of North America and the west of Europe. We should take this into consideration if we need to build some global distributed services. Network is not “free”. Network takes time.
As I found out during writing this post, this talk is given 7 years ago at 2009. All the numbers are based on a mid-range PC at that time[8]. So the numbers can be smaller now and there are also some more things to cover. I think it would be better if we have somewhere to keep all these figures in relation to design updated. Anyway, the exact numbers here are not as important as the differences in magnitude as you move up and down the table.
Decomposition a Design
I think it is rough to just summarize how to decompose a design since it is based on the knowledge of operation systems and the actual experience on building a performance significant system. For those who do not have them, this topic would be better explained in examples.
Example 1
For example, suppose we are going to generate an image result page that has 30 thumbnails in it. We definitely have various of available solutions. The very basic one can be reading the thumbnails serially from disk and show them. How can we decompose it? Well, for each thumbnail, we need to seek it on disk, and then read. With the average size of a thumbnail given, which is 256k, we can estimate the time cost:
560ms is definitely too long since whatever latency larger than 100ms is noticeable to user. How can we improve that? Obviously, by taking another look at the first design, we shall notice that there were no order requirments for those thumbnails, so that the thumbnails other than the current one do not need to wait. We can read them all at the same time. So this process can be boosted by reading thumbnails with one thread for each in parallel instead. How long does that take?
10 ms/seek + 256 k read / 30 MB/s = 18 ms
Of course, 256 k is just an average size. The estimation above ignores the variance. The full generation time depends on the largest thumbnail which takes longer to read. So we can imagine the real time cost might be much higher
Besides these two solutions, there is still potential to make the design even faster. If we take another look at the second design, we know that the bottleneck is that everything is on disk. What if we cache the thumbnails in memory? As long as the image size is not that big, we can put all of them in memory with 256 k * 30 = 6 ~ 7 MB space. Comparing to the large amount of memory we have on modern machines, it is totally acceptable. The time cost here would be:
100 ns/main memory reference + 256 k read / 4000 MB/s = 64.1 us
Example 2
The problem is “How long does it take to quicksort 1 GB of 4 byte numbers”. This is a pure time cost estimation question, as we already know the implementation of quicksort. So how can we decompose the steps?
First we need to figure out how many numbers we have, which is the input length n. 10^9 byte is roughly 2^30.
n = 2^30 / 4 = 2^28
Then we know the time complexity of quicksort it O(nlogn) and the basic step of quicksort is comparison. So the number of comparisons is around:
2^28 * log(2^28) ≈ 2^33 (Here 2^4 < log(2^28) = 28 < 2^5 and we take the larger one).
Around half of the comparisons will mispredict. So
2^32 mispredicts * 5 ns/mispredict = 21 seconds
Another thing to consider is the memory bandwidth. Suppose the quicksort should be sequential, and the machine we run this sorting have 4GB memory. So
As a result, it should take around 30 secs to sort 1 GB on one CPU machine with 4 GB memory.
Summary
In this post I shared a method by Jeff Dean to estimate time cost of a design, named “Back of the Envelope Calculation”. The estimation consists of mainly two steps: 1) Knowing the time cost of basic steps 2) Decomposing a design into those basic steps. Then we will be able to get an intuitive assessment on our possible designs and choose the best one.
The “Back of the Envelope Calculation” here focuses on time cost. Another interesting topic is memory usage estimation, which is also widely used before actual implementation. I remembered seeing my former tech lead doing this on a tiny piece of post-it paper and was totally fascinated. I told myself I would also be that kind of engineer one day. So stay tuned on the next topic: Memory Usage Estimation.
]]>
<p>So, I continued the journey on learning about System Design and found another very good resource. It is a talk by Jeff Dean at Stanford n
Ways to Build A Distributed Systemhttp://blog.kiyanpro.com/2016/09/13/system_design/Ways-to-Build-A-Distributed-System/2016-09-13T20:58:24.000Z2017-07-04T19:34:24.000ZEvery engineer should learn about distributed system design, since it is not only the path to next career level, but a necessary ability to build a large-scale application according to use cases and specifications as well. Without a proper design, it would be impossible to implement and manage such a system afterwards.
Today I read through “The Twitter Problem”[1] on hiredintech.com and found it truly useful and easy to understand. This post is a summary on the classic problems and solutions when building a scalable system. These problems are generally met in most of the large applications and are well solved by those extraordinary predecessors.
Techniques
These techniques are divided into two parts: 1) Handling user requests 2) Storing the data.
Handling user requests
Suppose we already know what kind of system, how many requests approximately, and how complex the requests are. What are the ways to handle these requests?
Comparing the technologies
One aspect can be the technologies used to implement the application. Some technologies are specially designed for high concurrency situation with less memory usage. This can enhance the load handled by a single machine. With some research on these technologies, we can know the number of requests that can be handled by a single machine for each of them. Then pick the one that performs the best.
One possible problem for this pre-research is time consuming. But it is worth it since the comparison result is reusable for the next design. Another downside can be that the best technology chosen may not be familiar to the team, or even not easier to pick up at all. All these factors should be considered before making the final decision.
Scaling Up
Scailing up means improving a single machine. Think about the aspects you can improve, such as the CPU, the memory, the disk and etc. Examples are like replace CPU with more cores, increase the size of memory, and upgrade to SSD drive.
This approach is useful in some cases, but after a given point, the hardware of one machine just is not capable of handling all the requests. It would also be a single point of failure if the machine goes down.
Scaling Out
Scaling out basically means adding more nodes and building a cluster. The load is distributed to a number of machines instead of one.
The approach is better generally, as it avoids single point failure and is easy to scale. When the current cluster cannot handle the load well, we can config a new machine and add it to the cluster. And if we know how many requests one node can handle, we can easily estimate how many nodes we need for a cluster as well.
Software Load Balancer
We can run a software load balancer on a machine in front of the application cluster. With proper configuration, the load balancer will forward the request to the actual node behind it in the cluster, thus distributing the load across. Classic software load balancers are nginx and HAProxy. Some cloud providers like AWS also provide traffic load balancing as a service.
Software load balancer definitely adds resiliency to an application. It is almost a must-have in distributed systems. But it can also be the bottleneck if the number of requests is too high and exceeds the capability of one single load balancer node.
DNS Load Balancer
We can config a DNS server to parse domain to different hosts. This DNS load balancer is in front of software load balancer and can forward requests to different software load balancers. In this way, the system can handle even more requests and further scale out.
Auto Scaling
Auto scaling is the ability to adjust the number of nodes in a cluster according current traffic level. Services like AWS and Heroku offer this kind of support.
This technique is specifically useful when it comes to unusual high traffic, where caching is not that efficient. The system will respond to the traffic and add more nodes if the traffic is too high, then reclaim those nodes when the traffic goes down to normal.
Storing the data
Estimation on data sizes
Assume that we know the relations between our data objects, we can assess the approximate size of the data to be stored. For example, in a simple twitter problem, we have 10 million users and each of them post 1 tweet per day. Each tweet contains 140 characters. If we assume 2 bytes per character, it will be 2 140 10bln = 2.6 TB for a day.
After a quick analysis on all possible data to be stored, there can be some data that takes up majority of the storage space. It is important to have a rough idea about the size of the data that the system will need to handle. Appropriate design decisions base on this.
Adding Indexes
In relational DB, adding indexes to a specific field enables executing quick queries joining tables. If we know some fields are used frequently in filtering queries, we definitely should build an index over the field to optimize the times for such queries.
After creating the indexes, write queries will become slightly slower. Considering the time we can save for heavy read operations it is still worth it.
Replication
With all the read requests coming to DB, we can have several replications that hold a copy of the data each.
This will help only if the write operations does not increase dramatically at the same time. Otherwise, it will be complicated to sync data between primary and replications.
Data partitioning (Sharding)
Divide the data in some way to several databases. After that, each DB will hold only part of the data, and also, share only part of the requests.
If we have several databases and each of them only has part of the data, the read and write will speed up since the load is smaller. But a way should be pre-defined before partitioning. Otherwise we won’t be able to know which DB a specific request should go to. And also, because the data size is smaller for each DB, it makes administration tasks like backups faster.
In-memory cache
In order to handle the incoming read requests, we can add an in-memory cache in front of the relational DB. The reason why this works is that DB reads directly from disk, and it is much slower than from memory. Even if the DB has its own caching mechanisms, a separate cache layer enables us to gain more control over what to be cached and how.
An in-memory cache will save us a lot of direct reads to DB. And since the results of most frequent requests is cached, the system is more resilient to usual traffic peaks.
Summary
These techniques from “The Twitter Problem” are described and analyzed at a very high level, so that we can have an general idea on each of them. This example also already showed what it is actually like to design a distributed system (or answer such problems in an interview). The next steps may be learning the actually theories behind each step mentioned, figuring out the reasons, and diving deep into each of those technologies.
]]>
<p>Every engineer should learn about distributed system design, since it is not only the path to next career level, but a necessary ability
Java SE 8 For the Really Impatient Serieshttp://blog.kiyanpro.com/2016/04/22/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient/2016-04-22T22:48:48.000Z2017-07-04T19:34:24.000ZRecently, I finished reading the book Java SE 8 For the Really Impatient. This book covers the main features introduced in Java SE 8, such as Lambda Expressions and Stream API. Also it shows some sweet small features that benefit every day work greatly, namely, the new d ate and time API, the concurrency enhancements, and etc.
This post is a guide for the reading notes of this series. You can jump right into a specific topic from here by clicking the numbers.
Lambda Expressions: 1. Talks about the fundamentals of lambda expressions in Java SE 8.
The Stream API: 2, 3, 4. Complete introduction on the Stream API.
Programming with Lambdas: 5, 6. Explains how to make use of lambda expressions and functional interfaces when building libraries.
The New Date and Time API: 7, 8. Introduces the new API, and how it iteracts with the old one.
Concurrency Enhancements: 9, 10, 11. Enhancements on java.util.concurrent.
Miscellaneous Goodies: 12, 13. Improvements on String, Number classes, Math, Collections, File IO, Annotations, and etc.
I skipped two chapters that I do not think I will use in near future: 1) Chapter 4 JavaFX 2) Chapter 7 the Nashorn JavaScript Engine. Also, Chapter 9 is specially for the good features in Java 7. I think the only way one grasps more of a language or skill is to grow with it. As Java is still evolving, we definitely should keep a close pace and embrace the improvements. You can read these chapters in the original book.
]]>
<p>Recently, I finished reading the book <em>Java SE 8 For the Really Impatient</em>. This book covers the main features introduced in Java
Philosophical Words in Kungfu Panda 3http://blog.kiyanpro.com/2016/04/18/words/Philosophical-Words-in-Kungfu-Panda-3/2016-04-18T18:45:50.000Z2016-09-17T22:23:18.000ZMy wife and I just watched Kungfu Panda 3 last weekend. Besides the fun parts, there are some words in it that I know they are right, but don’t fully understand. Maybe you feel the same. Here are a list of them.
Words
1
你何时才能领悟 索取越多 收获越少 When will you realize, the more you take, the less you have.
2
如果你只做你力所能及的事 你就没法进步 If you only do what you can do you’ll never be more than you are now.
3
你连自己是谁都不知道 You don’t even know who you are. 你说啥 我当然知道 我是神龙大侠 What do you….? Of course I do. I’m the Dragon Warrior. 那神龙大侠究竟意味着什么呢 And what exactly does that mean Dragon Warrior? 意味着…我要四处闯荡 拳打脚踢 It means…you know… just going around and punching and kicking 保卫家园什么的 Defending the valley and stuff. 拳打脚踢 Punching and kicking? 你认为这就是乌龟大师看中你的原因吗 You think that is what the great Master Oogway saw for you? 一个五百年的预言选中了你 A five hundred year prophecy full-filled 难道就是让你耍耍花拳绣腿 so you can spend your days… 满镇子乱跑跟兔子耍帅吗 Kicking butt? And running through town high-fiving bunnies?
4
乌龟曾在一个山洞里打坐整整三十年 Oogway sat alone in a cave for thirty years 只为弄清一个问题 asking one question 我是谁 Who am I?
5
我没让你变成我这样 I’m not trying to turn you into me. 我是让你变成你自己 I’m trying to turn you into you.
6
但你们不必像我 But you don’t have to be. 师父当初就是这个意思 我不必把你们变成另一个我 That’s what Shifu meant. I don’t have to turn you into me. 我要做的是激发你们自身的潜能 I have to turn you into you!
7
伙计们 展现出自己最好的水平就是你们真正的优势 You guys, your real strength comes from being the best you you can be. 那么 你是谁 你擅长什么 So, who are you? What are you good at? 你热衷什么 何为你的个人特色 What do you love? What makes you you?
8
我们初次见面的那一天 On the first day we met… 我看到了功夫的未来 I saw the future of kung fu. 也看到了过往 And the past. 我看到了那只能将两者合二为一的熊猫 I saw the panda who could unite them both. 这就是我选你的原因 阿宝 That is why I chose you, Po. 你结合了阴阳两极 Both sides of the Yin and Yang. 也是我真正的继承者 And my true successor.
Summary
Try to dive into these words and think. Think about who I am, how I can become better me, how I can help others find themselves and become better themselves. Find the real self first, then forget it and just be it. More importantly, how to combine the two sides of things, negate nothing, exlude nothing.
]]>
<p>My wife and I just watched Kungfu Panda 3 last weekend. Besides the fun parts, there are some words in it that I know they are right, but
Marvel What Does Search Rate Mean?http://blog.kiyanpro.com/2016/04/15/elasticsearch/Marvel-What-Does-Search-Rate-Mean/2016-04-15T23:38:38.000Z2017-07-04T19:34:24.000ZProblem
Elasticsearch provides a handy monitoring tool named Marvel. It is pretty easy to setup. But when it comes to real monitoring, you will realize that those metrics in dashboard are so confusing. They are not consistent with the actual QPS you sent to the cluster. You don’t really know what they refer to.
Solution
I googled it. But unfortunately there was no answer at that time. The only thing I got is a post on Marvel forum where somebody was as confused as me.
Then I tried to find the source code of Marvel. But I couldn’t find anything either because it is not opensourced. I really think Marvel has so many more improvements needed. They really should opensource it.
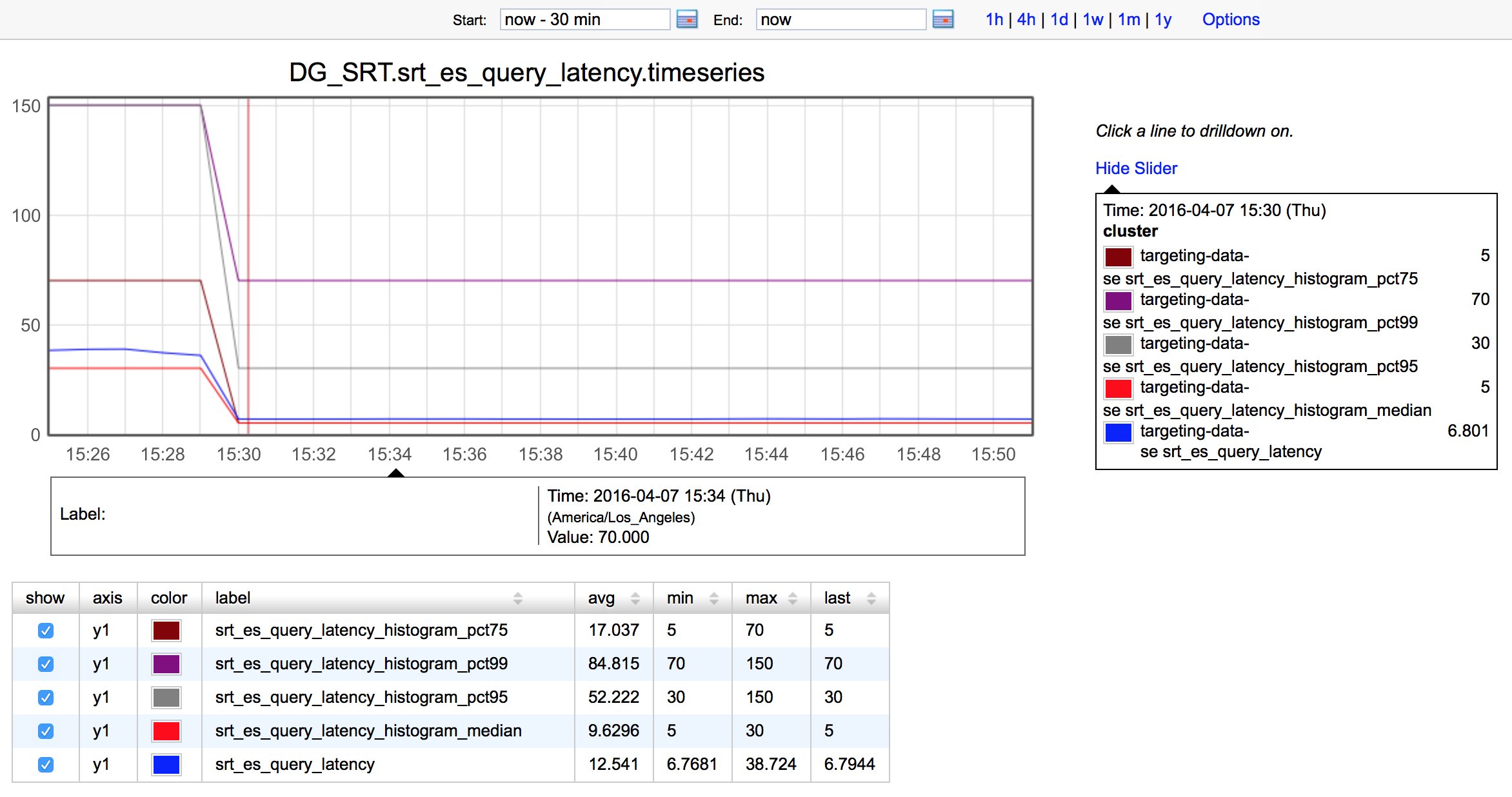
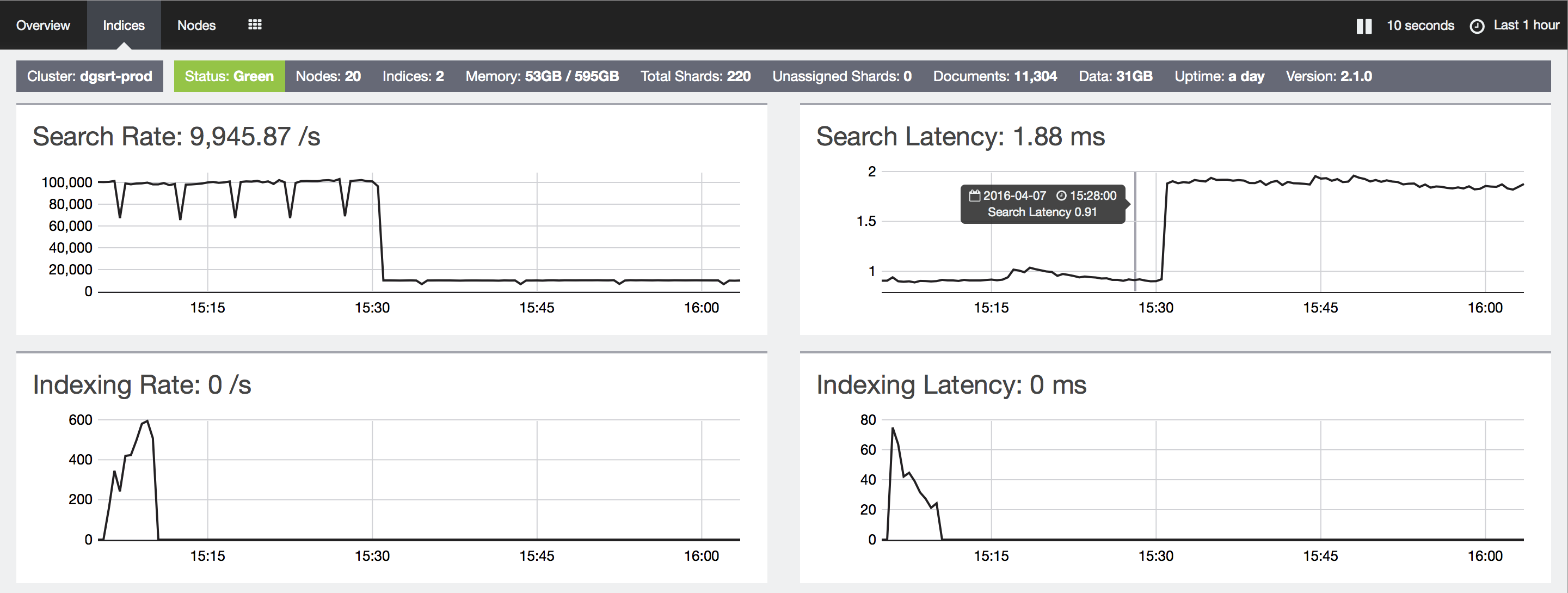
The answer came to me when I was struggling with the search performance. I reindexed all the data to try whether it would affect performance. To my surprise, after I changed to a single shard, the average search latency dropped from around 30ms to 7ms. And the search rate also drops to around 10k/s, which is exactly the estimation value of requests I sent to Elasticsearch cluster. All the mysteries disappeared and everything became crystal clear.
The first one is “Search Rate”. When the index had 10 shards, it was about 10 times the actual requests. When the index has only 1 shard, it was almost the same as the actual request.
Then “Search Latency”. When the index had 10 shards, it was around 0.9ms, but the end to end latency was around 30ms. When single shard, it goes up to 1.88ms, while the end to end latency is merely 7ms. That’s probably because the amount of data of each shard increases because of fewer shards, hence the longer search in each shard. But there is no need to merge result anymore. Here, we can see how badly merging result affects search performance.
“Index Rate” and “Indexing Latency” are the same.
Summary
The meanings are listed below:
Search Rate: for a single index, it’s number of lookups per second * number of shards. For multiple indices, it’s the sum of the search rate of each index.
Search Latency: Average latency within each shard.
Indexing Rate: for a single index, it’s number of indexing per second * number of shards. For multiple indices, it’s the sum of the indexing rate of each index.
Indexing Latency: Average latency within each shard.
You can verify the conclusions above by changing the number of shards of an index and see how it changes afterwards. Feel free to let me know if there is anything wrong.
]]>
<h2 id="Problem"><a href="#Problem" class="headerlink" title="Problem"></a>Problem</h2><p>Elasticsearch provides a handy monitoring tool nam
Java SE 8 For the Really Impatient, Note 13http://blog.kiyanpro.com/2016/04/04/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-13/2016-04-04T22:34:48.000Z2017-07-04T19:34:24.000ZChapter 8 Miscellaneous Goodies
Working with Files
Java 8 brings a small number of convenience methods that use stream for reading lines from files and for visiting directory entries. Also, there is an official way of performing Base64 encoding.
Streams of Lines
Files.lines: read the lines of a file lazily. It yields a stream of strings, one per line of input:
As soon as the first line containing password is found, no further lines are read from the underlying file.
Files.lines defaults to UTF-8, unlike FileReader which opens files in local character encoding. You can specify other encodings by supplying a Charset argument.
The Stream interface extends AutoCloseable. The Files.lines method produces a stream whose close method closes the file. The easiest way to make sure the file in indeed closed is to use a Java 7 try-with-resources block:
If an IOException occurs as the stream fetches the lines, that exception is wrapped into an UncheckedIOException which is thrown out of the stream operation.
If you want to read lines from a source other than a file, use the BufferedReader.lines method instead:
1
2
3
4
try (BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream()))) {
Stream<String> lines = reader.lines();
...
}
With this method, closing the resulting stream does not close the reader. So you must place the BufferedReader object, and not the stream object, into the header of the try statement.
Streams of Directory Entries
Files.list: returns a Stream<Path> that reads the entries of a directory. The directory is read lazily, making it possible to efficiently process directories with huge numbers of entries.
// Contains all descendants, visited in depth-first order
}
You can limit the depth of the tree by calling Files.walk(pathToRoot, depth). Both walk methods have a varargs parameter of type FileVistOption..., but there is currently only one option you can supply: FOLLOW_LINKS to follow symbolic links.
If you filter the paths returned by walk and your filter criterion involves the file attributes stored with a directory, such as size, creation time, or type (file, directory, symbolic link), then use the find method instead. Call it with a predicate function that accepts a path and a BasicFileAttributes object. The only advantage is efficiency, since the directory is being read anyway, the attributes are readily available.
Base64 Encoding
The Base64 encoding encodes a sequence of bytes into a (longer) sequence of printable ASCII characters. Java 8 provides a standard encoder and decoder.
Normally, an encoded string has no line breaks, but the MIME standard used for email requires a “\r\n” every 76 characters.
For encoding, request a Base64.Encoder with one of the static methods getEncoder, getUrlEncoder, or getMimeEncoder of the Base64 class.
That class has methods to encode an array of bytes or a NIO ByteBuffer.
Annotations are tags inserted into the source code that some tools can process.
Java 8 has two enhancements to annotaion processing: repeated annotations and type use annotations. Moreover, reflection has been enhanced to report method parameter names. This has the potential to simplify annotations on method parameters.
Repeated Annotations
When annotations were first created, they were envisioned to mark methods and fields for processing.
1
2
3
4
5
6
// Call after construction
@PostConstructpublicvoidfetchData(){ ... }
// Inject resource here
@Resource("jdbc:derby:sample")
private Connection conn;
In this context, it made no sense to apply same annotation twice. You can’t inject a field in two ways. Different annotations on the same element are fine and quite common:
1
2
@Stateless@Path("/service")
publicclassService{ ... }
Soon, more and more uses for annotations emerged, leading to situations where one would have liked to repeat the same annotation. E.g.,
1
2
3
4
@Entity
@PrimaryKeyJoinColumn(name="ID")
@PrimaryKeyJoinColumn(name="REGION")
publicclassItem{ ... }
Since that wasn’t possible, the annotations were packed into a container annotation, like this:
1
2
3
4
5
6
@Entity
@PrimaryKeyJoinColumns({
@PrimaryKeyJoinColumn(name="ID")
@PrimaryKeyJoinColumn(name="REGION")
})
publicclassItem{ ... }
This is no longer necessary in Java 8. If your framework provider has enabled repeated annotations, you can just use them.
For a framework implementor, the AnnotatedElement interface has a method that gets the annotation of type T, if present.
1
public <T extends Annotation> T getAnnotation(Class<T> annotationClass)
What should the method do if multiple annotations of the same type are present? To solve this problem, the inventor of a repeatable annotation must
Annotate the annotation as @Repeatable
Provide a container annotation
E.g., for a simple unit testing framework, we might define a repeatable @TestCase annotation, to be used like this:
1
2
3
@TestCase(params="4", expected="24")
@TestCase(params="0", expected="1")
publicstaticlongfactorial(int n){ ... }
Here is how annotation can be defined:
1
2
3
4
5
6
7
8
9
@Repeatable(TestCases.class)
@interface TestCase {
String params();
String expected();
}
@interface TestCases {
TestCase[] value();
}
Whenever the user supplies two or more @TestCase annotations, they are automatically wrapped into a @TestCases annotation.
When annotation processing code calls element.getAnnotation(TestCase.class) on the element representing the factorial method, null is returned. This is becasue the element is actually annotated with the container annotation TestCases.
When implementing an annotation processor for your repeatable annotation, you will find it simpler to use the getAnnotationsByType method. The call element.getAnnotationsByType(TestCase.class) “looks through” any TestCases container and gives you an array of TestCase annotations.
Type Use Annotations
Prior to Java 8, an annotation was applied to a declaration. A declaration is a part of code the introduces a new name.
1
2
3
@EntitypublicclassPerson{ ... }
@SuppressWarnings("unchecked") List<Person> people = query.getResultList();
In Java 8, you can annotate any type use. This can be useful in combination with tools that check for common programming errors. Suppose you annotated variables that you never want to be null as @NonNull. A tool can check that the following is correct:
1
2
3
private@NonNull List<String> names = new ArrayList<>();
...
names.add("Fred"); // No possibility of a NullPointerException
The tool should detect any statement that might cause names to be null.
1
2
names = null; // Null checker flags this as an error
names = readNames(); // OK if readNames returns a @NonNull String
The null checker in the Checker Framework assumes that any nonlocal variables are implicitly @NonNull, but that local variables might be null unless the code shows otherwise. If a method may return a null, it needs to be annotated as @Nullable.
How can one express that the list elements should be non-null?
1
private List<@NonNull String> names;
It is this kind of annotation that was not possible before Java 8 but has now become legal.
Type use annotations can appear in the following places:
With generic type arguments: List<@NonNull String>, Comparator.<@NonNull String>reverseOrder()
In any position of an array: @NonNull String[][] words(words[i][j] is not null), String @NonNull [][] words(words is not null), String[] @NonNull [] words(words[i] is not null)
With superclasses and implemented interfaces: class Image implements @Rectangular Shape
With constructor invocations: new @Path String("/usr/bin")
With casts and instanceOf checks: (@Path String) input, if (input instanceOf @Path String). (The annotations are only for use by external tools. They have no effect on the behavior of a cast or an instanceOf check.)
With exception specifications: public Person read() throws @Localized IOException
With wildcards and type bounds: List<@ReadOnly ? extends Person>, List<? extends @ReadOnly> Person
With method and constructor references: @Immutable Person::getName
There are a few type positions that cannot be annotated:
1
2
@NonNull String.class // cannot annotate class literal
More for extended type checking can be found at Checker Framework tutorial.
Method Parameter Reflection
The names of parameters are now available through reflection. Consider a typical JAX-RS method:
1
Person getEmployee(@PathParam("dept") Long dept, @QueryParam("id") Long id)
In almost all cases, the parameter names are the same as the annotation arguments, or they can be made to be the same. If the annotation processor could read the parameter names, then one could simply write
1
Person getEmployee(@PathParam Long dept, @QueryParam Long id)
This is possible in Java 8, with the new class java.lang.relect.Parameter.
Unfortuantely, for the necessary information to appear in the classfile, the source must be compiled as javac -parameters SourceFile.java.
Miscellaneous Minor Changes
Null Checks
The Objects class has static predicate methods isNull and nonNull that can be useful for streams.
1
2
3
4
5
// checks whether a stream contains a null
stream.anyMatch(Objects::isNull);
// filter null
stream.filter(Objects::nonNull);
Lazy Messages
The log, logp, severe, warning, info, config, fine, finer, and finest methods of java.util.Logger class now support lazily constructed messages.
1
logger.finest("x: " + x + ", y: " + y);
The message string is formatted even when the logging level is such that it would never be used. Instead, use
1
logger.finest(() -> "x: " + x + ", y: " + y);
Now the lambda expression is only evaluated at the FINEST logging level, when the cost of the lambda invocation is presumably the least of one’s problems.
The requireNonNull of the Objects class also has a version that computes the message string lazily.
1
this.directions = Objects.requireNonNull(directions, () -> "directions for " + this.goal + " must not be null");
In the common case that directions is not null, this.directions is simply set to directions. If directions is null, the lambda is invoked, and a NullPointerException is thrown whose message is the returned string.
Regular Expressions
Java 7 introduced named capturing groups.
1
(?<city>[\p{L} ]+),\s*(?<state>[A-Z]{2})
In Java 8, you can use the names in the start, end, and group methods of Matcher:
1
2
3
4
5
Matcher matcher = pattern.matcher(input);
if (matcher.matches()) {
String city = matcher.group("city");
...
}
The Pattern class has a splitAsStream method that splits a CharSequence along a regular expression.
1
2
String contents = new String(Files.readAllBytes(path), StandardCharsets.UTF_8);
Stream<String> words = Pattern.compile("[\\P{L}]+").splitAsStream(contents);
The method asPredicate can be used to filter strings that match a regular expression:
A locale specifies everything you need to know to present information to a user with local preferences concerning language, date formats, and so on.
A locale is composed of up to five components:
A language, specified by two or three lowercase letters
A script, specified by four letters with an intial uppercase
A country, specified by two uppercase letters or three digits
Optionally, a variant
Optionally, an extension. Extensions describe local preferences for calendars, numbers, and so on
Since Java 7 you can simply call Locale.forLanguageTag("en-US"). Java 8 adds methods for finding locales that match user needs.
A language range is a string that denotes the locale characteristics that a user desires, with * for wildcards. One can optionally specify a weight between 0 and 1 when constructing a Locale.LanguageRange.
Given a list of weighted language ranges and a collection of locales, the filter method produces a list of matching locales, in descending order of match quality.
1
2
3
4
5
6
7
// A list containing the Locale.LanguageRange objects for the given strings
The Date, Time, and Timestamp classes in the java.sql package have methods to convert from and to their java.time analogs LocalDate, LocalTime, and LocalDateTime.
The Statement class has a method executeLargeUpdate for executing an update whose row count exceeds Integer.MAX_VALUE.
JDBC 4.1 specified a generic method getObject(column, type) for Statement and ResultSet, where type is a Class instance. E.g., URL url = result.getObject("link", URL.class) retrieves a DATALINK as a URL. Now the corresponding setObject method is provided as well.
]]>
<h1 id="Chapter-8-Miscellaneous-Goodies"><a href="#Chapter-8-Miscellaneous-Goodies" class="headerlink" title="Chapter 8 Miscellaneous Goodie
Java SE 8 For the Really Impatient, Note 12http://blog.kiyanpro.com/2016/03/31/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-12/2016-03-31T22:26:27.000Z2017-07-04T19:34:24.000ZChapter 8 Miscellaneous Goodies
Key points:
Joining strings with a delimiter is finally easy: String.join(",", "a", "b", "c") instead of a + ", " + b + ", " + c".
Integer types now support unsigned arithmetic.
The Math class has methods to detect integer overflow.
Use Math.floorMod(x, n) instead of x % n if x might be negative.
There are a few mutators in Collection(removeIf) and List(replaceAll, sort).
Files.lines lazily reads a stream of lines.
Files.list lazily lists the entries of a directory, and Files.walk traverses them recursively.
There is finally official support for Base64 encoding.
Annotations can now be repeated and applied to type uses.
Convenient support for null parameter checks can be found in the Object class.
Strings
A common task is to combine several strings, separating them with a delimiter such as “, “ or “/“. This has now been added to Java 8. The strings can come from an array or an Iterable<? extends CharSequence>.
1
2
3
String joined = String.join("/", "usr", "local", "bin"); // "usr/local/bin"
Think of join as the opposite of the String.split instance method.
Number Classes
Since Java 5, each of seven numeric primitive type wrappers(i.e, not Boolean) had a static SIZE field that gives the size of the type in bits.
There is now BYTES field that reports the size in bytes.
All eight primitive type wrappers now have static hashCode methods that return the same hash code as the instance methods, but without the need for boxing.
The five types Short, Integer, Long, Float, and Double now have static methods sum, max and min, which can be useful as reduction functions in stream operations.
The Boolean class has static logicalAnd, logicalOr, and logicalXor for the same purpose.
Integer types now support unsigned arithmetic. E.g., instead of having a Byte represent the range from -128 to 127, you can call the static method Byte.toUnsignedInt(b) and get a value between 0 and 255. The Byte and Short classes have methods toUnsignedInt, and Byte, Short and Integer have methods toUnsignedLong.
The Integer and Long classes have methods compareUnsigned, divideUnsigned, and remainderUnsigned to work with unsigned values. Integer multiplication would overflow with unsigned integers larger than Integer.MAX_VALUE, so you should call toUnsignedLong and multiply them as long values.
The Float and Double classes have static methods isFinite. The call Double.isFinite(x) returns true if x is not infinity, negative infinity, or a NaN. In the past, you had to call the instance methods isInfinite and isNaN to get the same result.
The BigInteger class has instance methods (long|int|short|byte)ValueExact that return the values as a long, int, short, or byte, throwing an ArithmeticException if the value is not within the target range.
New Mathematical Functions
The Math class provides several methods for “exact” arithmetic that throw an exception when a result overflows. E.g., 100000 * 100000 quietly gives the wrong result 1410065408, whereas multiplyExact(100000, 100000) throws an exception. The provided methods are (add|subtract|multiply|increment|decrement|negate)Exact with int and long parameters. The toIntExact method converts a long to the equivalent int.
The floorMod and floorDiv methods aim to solve a long-standing problem with integer remainders: n % 2 is -1 when n is negative and odd. floorMod(position + adjustment, 12) always yields a value between 0 and 11.
Unfortunately, floorMod gives negative results for negative divisors, but that situation doesn’t often occur in practice.
The nextDown method, defined for both double and float parameters, gives the next smaller floating-point number for a given number. E.g., if you promise to produce a number < b, but you happen to have computed exactly b, then you can return Math.nextDown(b).(The corresponding Math.nextUp method exists since Java 6.)
All methods described in this section also exist in the StrictMath class.
Collections
Methods Added to Collection Classes
Methods Added to Collections Classes and Interface in Java 8, other than the stream, parallelStream, and spliterator
Class/Interface
New Methods
Iterable
forEach
Collection
removeIf
List
replaceAll, sort
Map
forEach, replace, replaceAll, remove(key, value)(removes only if key mapped to value), putIfAbsent, compute, computeIf(Absent | Present), merge
Iterator
forEachRemaining
BitSet
stream
removeIf: can be thought of as the opposite of filter, removing rather than producing all matches and carrying out the removal in place. The distinct method would be costly to provide on arbitrary collections.
The List interface has a replaceAll method, which is an in-place equivalent of map, and a sort method that is obviously useful.
The Iterator interface has a forEachRemaining method that exhausts the iterator by feeding the remaining iterator elements to a function.
The BitSet class has a method that yields all members of the set as a stream of int values.
Comparators
The static comparing method takes a “key extractor” function that maps a type T to a comparable type (such as String). The function is applied to the objects to be compared, and the comparison is then made on the returned keys.
If your key function can return null, use nullsFirst or nullsLast adapters. These static methods take an existing comparator and modify it so that it doesn’t throw an exception when encountering null values but ranks them as smaller or larger than regular values. Suppose getMiddleName returns a null when a person has no middle name. Then you can use Comparator.comparing(Person::getMiddleName(), Comparator.nullsFirst(...)).
The naturalOrder method makes a comparator for any class implementing Comparable. A Comparator.<String>natrualOrder() is what we need.
The static reverseOrder method gives the reverse of the natural order. To reverse any comparator, use the reversed instance method. anturalOrder().reversed() is the same as reverseOrder().
The Collections Class
Java 6 introduces NavigableSet and NavigableMap interfaces that take advantage of the ordering of the elements or keys, providing efficient methods to locate, for any given value v, the smallest element >= or > v, or the largest element <= or < v.
The Collections class supports these interfaces as it does other collections, with methods (unmodifiable|synchronized|check|empty)Navigable(Set|Map).
A checkedQueue wrapper has also been added. As as reminder, the checked wrappers have a Class parameter and throw a ClassCastException when you insert an element of the wrong type. These classes are intended as debugging aids. Suppose you declare a Queue<Path>, and somewhere in your code there is a ClassCastException trying to cast a String to a Path. If you temporarily replace the queue with a CheckedQueue(new LinkedList<Path>, Path.class), then every insertion is checked at runtime, and you can locate the faulty insertion code.
There are emptySorted(Set|Map) methods that give lightweight instances of sorted collections, analogous to the empty(Set|Map) methods.
]]>
<h1 id="Chapter-8-Miscellaneous-Goodies"><a href="#Chapter-8-Miscellaneous-Goodies" class="headerlink" title="Chapter 8 Miscellaneous Goodie
Java SE 8 For the Really Impatient, Note 11http://blog.kiyanpro.com/2016/03/30/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-11/2016-03-30T21:56:21.000Z2017-07-04T19:34:24.000ZChapter 6 Concurrency Enhancements
Parallel Array Operations
Arrays class now has a number of parallelized operations.
Arrays.parallelSort: sort an array of primitive values or objects.
1
2
3
String contents = new String(Files.readAllBytes(Paths.get("alice.txt")), StandardCharsets.UTF_8);
String[] words = contents.split("[\\P{L}]+"); // Split along nonletters
Arrays.parallelSort(words);
You can supply a Comparator.
You can supply the bounds of a range.
1
Arrays.parallelSort(values, values.length / 2, values); // Sort the upper half
parallelSetAll: fills an array with values that are computed from a function. The function receives the element index. There are versions for all primitive type arrays and for object arrays.
1
Arrays.parallelSetAll(values, i -> i % 10);
parallelPrefix: replaces each array element with the accumulation of the prefix for a given associative operation.
1
2
3
// [1, 2, 3, 4, ...] and x
Arrays.parallelPrefix(values, (x, y) -> x * y);
// [1, 1 x 2, 1 x 2 x 3, 1 x 2 x 3 x 4, ...]
This can be parallelized in this way: join neighboring elements first, then update the indicated elements by multiplying them with elements that are one or two positions below.
Completable Futures
The java.util.concurrent library provides a Future<T> interface to denote a value of type T that will be available at some point in the future.
Completable futures make it possible to compose asynchronous operations.
Futures
Consider a method that reads a web page in a separate thread, which is going to take a while. When you call it, the method returns right away, and you have a Future<String>.
1
2
3
public Future<String> readPage(URL url)
Future<String> contents = readPage(url);
Suppose we want to extract all URLs from the page in order to build a web crawler. We have a class Parser with a method
1
publicstatic List<URL> getLinks(String page)
How can we apply it to the future object? First, call the get method on the future to get its value when it becomes available. Then, process the result:
1
2
String page = contents.get(); // blocking
List<URL> links = Parser.getLinks(page);
No better off than with a method public String readPage(URL url) that blocks until the result is available.
CompletableFuture
Provides the feature to set “when the result becomes available, here is how to process it”. A CompletableFuture has a method thenApply to which you can pass the post-processing function.
The thenApply method doesn’t block either. It returns another future. When the first future has completed. its result is fed to the getLinks method, and the return value of that method becomes the final result.
This composability is the key aspect of the CompletableFuture class. Composing future actions solves a problem in programming asynchronous applications.
The Composition Pipeline
Pipeline of futures starts out by generating a CompletableFuture, usually with the static method supplyAsync. That method requires a Supplier<T>, that is, a function with no parameters yielding a T. The function is called on a separate thread.
runAsync: takes a Runnable, yielding a CompletableFuture<Void>. Useful if you simply want to schedule one action after another, without passing data between them.
All methods ending in Async have two variants. One runs the provided action on the common ForkJoinPool. The other has a parameter of type java.util.concurrent.Executor, and it uses the given executor to run the action.
Next, you can call thenApply or thenApplyAsync to run another action, either in the same thread or another. With either method, you supply a function and you get a CompletableFuture<U>, where U is the return type of the function.
You can have additional processing steps. Eventually, you will be done. thenAccept: takes a Consumer, a function with return type void. Ideally, you would never call get on a future. The last step in the pipeline simply deposits the result where it belongs.
You don’t explicitly start the computation. The static supplyAsync method starts it automatically, and the other methods cause it to be continued.
Composing Asynchronous Operations
Adding an Action to a CompletableFuture Object
Method
Parameter
Description
thenApply
T -> U
Apply a function to the result
thenCompose
T -> CompletableFuture
Invoke the function on the result and execute the returned future
handle
(T, Throwable) -> U
Process the result or error
thenAccept
T -> void
Like thenApply, but with void result
whenComplete
(T, Throwable) -> void
Like handle, but with void result
thenRun
Runnable
Execute the Runnable with void result
For each method shown, there are also two Async variants.
T -> U is Function<? super T, U>
The calls CompletableFuture<U> future.thenApply(f) and CompletableFuture<U> future.thenApplyAsync(f) return a future that applies f to the result of future when it is available. The second call runs f in another thread.
thenCompose: takes a function T -> CompletableFuture<U>.
Here we have two functions: T -> CompletableFuture and U -> CompletableFuture. Clearly, they compose to a function T -> CompletableFuture by calling the second function when the first one has completed. That is exactly what thenCompose does.
1
2
3
public CompletableFuture<String> readPage(URL url)
public CompletableFuture<URL> getURLInput(String prompt)
handle: handles an exception thrown in a CompletableFuture. The supplied function is called with the result (or null if none) and the exception (or null if none), and it gets to make sense of the situation.
Combining Multiple Composition Objects
Method
Parameters
Description
thenCombine
CompletableFuture, (T, U) -> V
Execute both and combine the results with the given function.
theAcceptBoth
CompletableFuture, (T, U) -> void
Like thenCombine, but with void result.
runAfterBoth
CompletableFuture<?>, Runnable
Execute the runnable after both complete.
applyToEither
CompletableFuture, T -> V
When a result is available from one or the other, pass it to the given function
acceptEither
CompletableFuture, T -> void
Like applyToEither, but with void result.
runAfterEither
CompletableFuture<?>, Runnable
Execute the runnable after one or the other completes.
static allOf
CompletableFuture<?>…
Complete with void result after all given futures complete.
static anyOf
CompletableFuture<?>…
Complete with void result after any of the given futures completes.
The first three methods run a CompletableFuture<T> and a CompletableFuture<U> action in parallel and combine the results.
The next three methods run two CompletableFuture<T> actions in parallel. As soon as one of them finishes, its result is passed on, and the other result is ignored.
The static allOf and anyOf methods take a variable number of completable futures and yield a CompletableFuture<Void> that completes when all of them, or any one of them, completes. No results are propagated.
Technically speaking, the methods accept parameters of CompletionStage, not CompletableFuture. That is an interface type with almost forty abstract methods, currently implemented only by CompletableFuture.
]]>
<h1 id="Chapter-6-Concurrency-Enhancements"><a href="#Chapter-6-Concurrency-Enhancements" class="headerlink" title="Chapter 6 Concurrency En
Java SE 8 For the Really Impatient, Note 10http://blog.kiyanpro.com/2016/03/29/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-10/2016-03-29T22:21:42.000Z2017-07-04T19:34:24.000ZChapter 6 Concurrency Enhancements
ConcurentHashMap Improvements
mappingCount: returns the size as a long in case it’s too large.
An attacker can slow down a program by crafting a large number of strings that hash to the same value. As of Java 8, the concurrent hash map organizes the buckets as trees, not lists, when the key type implements Comparable, guaranteeing O(log(n)) performance.
map.put(word, newValue); // not atomic, another thread can be updating at the same time
replace: replacing a known old value with a new one.
1
2
3
4
do {
oldValue = map.get(word);
newValue = oldValue == null ? 1 : oldValue + 1;
} while (!map.replace(word, oldValue, newValue));
You can also use a ConcurrentHashMap<String, AtomicLong> or, with Java 8, a ConcurrentHashMap<String, LongAdder>
1
2
map.putIfAbsent(word, new LongAdder()); // ensures that a LongAdder is there
map.get(word).increment();
compute: called with a key and a function to compute the new value. That function receives the key and the associated value, or null if there is none, and it computes the new value.
1
map.compute(word, (k, v) -> v == null ? 1 : v + 1);
You cannot have null values in a ConcurrentHashMap. There are many methods that use a null value as an indication that a given key is not present in the map.
computeIfPresent: only computes a new value when there is already an old one. computeIfAbsent: only computes a new value when there isn’t yet an old one.
A map of LongAdder counters can be updated with
1
2
// LongAdder constructor is only called when a new counter is actually needed
map.computeIfAbsent(word, k -> new LongAdder()).increment();
merge: can do something special when a key is added for the first time. It has a particular parameter for the initial value that is used when the key is not yet present. Otherwise, the function that you supplied is called, combining the existing value and the initial value. (Unlike compute, the function does not process the key.)
If the function that is passed to compute or merge returns null, the existing entry is removed from the map.
The function should not do a lot of work, otherwise other updates to the map may be blocked. And it should also not update other parts of the map.
Bulk Operations
The bulk operations travers the map and operate on the elements they find as they go along. No effort is made to freeze a snapshot of the map in time. Unless you happen to know that the map is not being modified while a bulk operation runs, you should treat its result as an approximation of the map’s state.
3 kinds of operations:
search:applies a function to each key and/or value, until the function yields a non-null result.
reduce: combines all keys and/or values, using a provided accumulation function.
forEach: applies a function to all keys and/or values.
Each operation has 4 versions:
searchKeys / reduceKeys / forEachKey: operates on keys
searchValues / reduceValues / forEachValue: operates on values
search / reduce / forEach: operates on keys and values
searchEntries / reduceEntries / forEachEntry: operates on Map.Entry objects
You need to specify a parallelism threshold with each of the operations. If the map contains more elements than the threshold, the bulk operation is parallelized. If you want to run single thread, use a threshold of Long.MAX_VALUE. If you want the max number of threads, use a threshold of 1.
Search
1
2
3
4
U searchKeys(long threshold, Function<? super K, ? extends U> f)
U searchValues(long threshold, Function<? super V, ? extends U> f)
U search(long threshold, BiFunction<? super K, ? super V, ? extends U> f)
U searchEntries(long threshold, Function<Map.Entry< K, V>, ? extends U> f)
Find the first word that occurs more than 1000 times
1
String result = map.search(threshold, (k, v) -> v > 1000 ? k : null);
The result is set to the first match, or to null if the search function returns null for all inputs.
2 variants of forEach: the first one simply applies a consumer function for each map entry:
The second takes an additional transformer function, which is applied first, and its result is passed to the consumer:
1
2
3
map.forEach(threshold,
(k, v) -> k + "->" + v, // Transformer
System.out::println); // Consumer
The transformer can be used as a filter. Whenever the transformer returns null, the value is silently skipped.
1
2
3
4
// only print large values
map.forEach(threshold,
(k, v) -> v > 1000 ? k + "->" + v : null, // Filter and transformer
System.out::println); // The nulls are not passed to the consumer
reduce: combines inputs with an accumulation function
1
2
// sum of all values
Long sum = map.reduceValues(threshold, Long::sum);
You can also supply a transformer function.
1
2
3
Integer maxLength = map.reduceKeys(threshold,
String::length, // Transformer
Integer::max); // Accumulator
The transformer can also be a filter.
1
2
3
Long count = map.reduceValues(threshold,
v -> v > 1000 ? 1L : null,
Long::sum);
The reduce operation returns null, if the map is empty, or all entries have been filtered out. If there is only one element, its transformation is returned, and the accumulator is not applied.
There are specializations for int, long and double outputs with suffix ToInt, ToLong, and ToDouble. You need to transform the input to a primitive value and specify a default value and an accumulator function. The default value is returned when the map is empty.
1
2
3
4
5
long sum = map.reduceValuesToLong(threshold,
Long::longValue, // Transformer to primitive type
0, // Default value for empty map
Long::sum // Primitive type accumulator
);
These specializations act differently from the object versions where there is only one element to be considered. Instead of returning the transformed element, it is accumulated with the default. Therefore, the default must be the neutral element of the accumulator.
Set Views
The static newKeySet method yields a Set<K> that is actually a wrapper around a ConcurrentHashMap<Km, Boolean>. (All map values are Boolean.TRUE.)
1
Set<String> words = ConcurrentHashMap.<String>newKeySet();
keySet: yields the set of keys. The set is mutable. If you remove the set’s elements, the keys(and their values) are removed from the map. But it doesn’t make sense to add elements to the key set, becase there would be no corresponding values to add. Java 8 adds a second keySet method to ConcurrentHashMap, with a default value, to be used when adding elements to the set:
1
2
Set<String> words = map.keySet(1L);
words.add("Java");
If “Java” wasn’t already present in words, it now has a value of one.
]]>
<h1 id="Chapter-6-Concurrency-Enhancements"><a href="#Chapter-6-Concurrency-Enhancements" class="headerlink" title="Chapter 6 Concurrency En
Java SE 8 For the Really Impatient, Note 9http://blog.kiyanpro.com/2016/03/29/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-9/2016-03-29T22:19:11.000Z2017-07-04T19:34:24.000ZChapter 6 Concurrency Enhancements
java.util.concurrent is a mix of useful utilities for the application programmer and power tools for library authors, without much effort to separate the two.
Key points:
Updating atomic variables has become simpler with the updateAndGet/accumulateAndGet methods.
LongAccumulator/DoubleAccumulator are more efficient than AtomicLong/AtomicDouble under high contention.
Updating entries in a ConcurrentHashMap has become simpler with the compute and merge methods.
ConcurrentHashMap now has bulk operations search, reduce, forEach, with variants operating on keys, values, keys and values, and entries.
A set view lets you use a ConcurrentHashMap as Set.
The Arrays class has methods for parallel sorting, filling, and prefix operations.
Completable futures let you compose asynchronous operations.
Atomic Values
java.util.concurrent.atomic package provided classes for lock-free mutation of variables since Java 5. You can safely generate a sequence of numbers like below:
1
2
3
publicstatic AtomicLong nextNumber = new AtomicLong();
// In some thread...
long id = nextNumber.incrementAndGet();
incrementAndGet: atomically increments the AtomicLong and returns the post-increment value.
If you want to make a more complex update, you have to use the compareAndSet method. Suppose you want to keep track of the largest value that is observed by different thread.
1
2
3
publicstatic AtomicLong largest = new AtomicLong();
Instead, compute the new value and use compareAndSet in a loop.
1
2
3
4
do {
oldValue = largest.get();
newValue = Math.max(oldValue, observed);
} while (!largest.compareAndSet(oldValue, newValue));
If another thread is also updating largest, it is possible the it has beat this thread to it. Then compareAndSet will return false without setting the new value. The loop tries again. Eventually, it will succeed replacing the existing value with the new one. The compareAndSet method maps to a processor operation that is faster than using a lock.
In Java 8, you can use a lambda expression.
1
2
3
largest.updateAndGet(x -> Math.max(x, observed));
// or
largest.accumulateAndGet(observed, Math::max);
The accumulateAndGet method takes a binary operator that is used to combine the atomic value and the supplied argument.
Also see getAndUpdate and getAndAccumulate the return the old value.
These methods are also provided for:
AtomicInteger
AtomicIntegerArray
AtomicIntegerFieldUpdater
AtomicLongArray
AtomicLongFieldUpdater
AtomicReference
AtomicReferenceArray
AtomicReferenceFieldUpdater
LongAdder and LongAccumulator can be used to solve the problem that a large number of threads accessing the same atomic values.
LongAdder: composed of multiple variables whose collective sum is the current value. Multiple threads can update different summands, and new summands are automatically provided when the number of threads increases. Efficient when the value of the sum is not needed until after all work has been done. If you anticipate high contention, you should simply use a LongAdder instead of an AtomicLong. Call increment to increment a counter, or add to add a quantity, and sum to retrieve the total.
1
2
3
4
5
6
7
8
9
final LongAdder adder = new LongAdder();
for (...)
pool.submit(() -> {
while (...) {
...
if (...) adder.increment();
}
});
long total = adder.sum();
increment does not return the old value which would undo the efficiency gain.
LongAccumulator: generalizes the idea to an arbitrary accumulation operaiton. Provide the operation and its neutral element in the constructor. Call accumulate to incorporate new values. Call get to obtain the current value.
1
2
3
LongAccumulator adder = new LongAccumulator(Long::sum, 0);
// In some thread...
adder.accumulate(value);
Internally, the accumulator has variables a1, a2, …, an. Each variable is initialized with the neutral element.
When accumulate is called with value v, then one of them is atomically updated as ai = ai op v, where op is the accumulation operation written in infix form. In the above example, a call to accumulate computes ai = ai + v for some i.
The result of get is a1 op a2 op … op an.
If you choose a different operation, you can compute maximum or minimum.
The operation must be associative and commutative, meaning that the final result must be independent of the order.
DoubleAdder and DoubleAccumulator work in the same way with double values.
StampedLock: can be used to implement optimistic reads. Not recommended to use locks.
First call tryOptimisticRead, upon which you get a “stamp”. Read your values and check whether the stamp is still valid(no other thread has obtained a write lock). If so, you can use the values. If not, get a read lock (which blocks any writers).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
publicclassVector{
privateint size;
private Object[] elements;
private StampedLock lock = new StampedLock();
public Object get(int n){
long stamp = lock.tryOptimisticRead();
Object[] currentElements = elements;
int currentSize = size;
if (!lock,validate(stamp)) { // Someone else had a write lock
stamp = lock.readLock(); // Get a pessimistic lock
currentElements = elements;
currentSize = size;
lock.unlockRead(stamp);
}
return n < currentSize ? currentElements[n] : null;
}
...
}
]]>
<h1 id="Chapter-6-Concurrency-Enhancements"><a href="#Chapter-6-Concurrency-Enhancements" class="headerlink" title="Chapter 6 Concurrency En
Java SE 8 For the Really Impatient, Note 8http://blog.kiyanpro.com/2016/03/25/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-8/2016-03-25T23:17:35.000Z2017-07-04T19:34:24.000ZChapter 5 The New Date and Time API
Date Adjusters
Compute dates such as “the first Tuesday of every month”.
TemporalAdjusters: provides a number of static methods for common adjustments. You pass the result of an adjustment method to the with method. with: returns a new LocalDate object without modifying the original.
Customize your own adjuster by implementing the TemporalAdjuster interface.
1
2
3
4
5
6
7
8
9
10
// computing the next weekday
TemporalAdjuster NEXT_WORKDAY = w -> {
LocalDate result = (LocalDate) w;
do {
result = result.plusDays(1);
} while (result.getDayOfWeek().getValue() >= 6);
return result;
};
LocalDate backToWork = today.with(NEXT_WORKDAY);
Note that the parameter of the lambda expression has type Temporal, and it must be cast to LocalDate. You can avoid this cast with the ofDateAdjuster method that expects a lambda of type UnaryOperator<LocalDate>.
Subtracts a number of hours, minutes, seconds, or nanoseconds to the LocalTime
plus, minus
Adds or subtracts a Duration
withHour, withMinute, withSecond, withNano
Returns a new LocalTime with the hour, minute, second or nanosecond changed to the given value
getHour, getMinute, getSecond, getNano
Gets the hour, minute, second, or nanosecond of this LocalTime
toSecondOfDay, toNanoOfDay
Returns the number of seconds or nanoseconds between midnight and this LocalTime
plus and minus operations wrap around a 24-hour day.
1
LocalTime wakeup = bedtime.plusHours(8);
LocalTime doesn’t concern itself with AM/PM. Deal by Formatter.
LocalDateTime: represents a date and time. Suitable for storing points in time in a fixed time zone. E.g., for a schedule of classes or events.
Zoned Time
Use ZonedDateTime if you need to make calculations that span the daylight savings time, or if you need to deal with users in different time zones.
ZoneId.getAvailableIds: find out all available time zones.
ZoneId.of(id): yields a ZoneId object you can use to turn a LocalDateTime object into a ZonedDateTime object by calling local.atZone(zoneId), or you can construct a ZonedDateTime by calling the static method ZonedDateTime.of(year, month, day, hour, minute, second, nano, zoneId).
Call Instant.atZone(ZoneId.of("UTC")) to get the ZonedDateTime at the Greenwich Royal Observatory. Or use another ZoneId to get it elsewhere on the planet.
ZonedDateTime Methods
Method
Description
now, of, ofInstant
These static methods construct a ZonedDateTime from the current time, or from a year, month, day, hour, minute, second, nanosecond(or a LocalDate and LocalTime), and ZoneId, or from an Instant and ZoneId
Returns a new ZonedDateTime, with one temporal unit changed to the given value
withZoneSameInstant, withZoneSameLocal
Returns a new ZonedDateTime in the given time zone, either representing the same instant or the same local time.
getDayOfMonth
Gets the day of the month (between 1 and 31).
getDayOfYear
Gets the day of the year (between 1 and 366).
getDayOfWeek
Gets the day of the week, returning a value of the DayOfWeek enumeration.
getMonth, getMonthValue
Gets the month as a value of the Month enumeration, or as a number between 1 and 12.
getYear
Gets the year, betweem -999,999,999 and 999,999,999
getHour, getMinute, getSecond, getNano
Gets the hour, minute, second, or nanosecond of this ZonedDateTime
getOffset
Gets the offset from UTC, as a ZoneOffset instance. Offsets can vary from -12:00 to 14:00. Some time zones have fractional offsets. Offsets change with daylight savings time.
toLocalDate, toLocalTime, toInstant
Yields the local date or local time, or the corresponding instant.
isBefore, isAfter
Comapres this ZonedDateTime with another
When daylight time starts, clocks are set forward by an hour.
1
2
3
4
5
ZonedDateTime skipped = ZonedDateTime.of(
LocalDate.of(2013, 3, 31),
LocalTime.of(2, 30),
ZonedId.of("Europe/Berlin")
); // constructs March 31 3:30
When daylight time ends, clocks are set back by an hour, and there are 2 instants with the same local time!
An hour later, the time has the same hours and minutes, but the zone offset has chagned.
Pay attentionwhen adjusting a date across daylight savings time boundaries. If you set a meeting for next week, don’t add a duration of 7 days:
1
ZonedDateTime nextMeeting = meeting.plus(Duration.ofDays(7)); // won't work with daylight savings time
Instead use the Period class:
1
ZonedDateTime nextMeeting = meeting.plus(Period.ofDays(7)); // OK
OffsetDateTime: represents times with an offset from UTC, but without time zone rules. Intended for specialized applications that specifically require the absence of those rules, such as certain network protocols. For human time, use ZonedDateTime.
Formatting and Parsing
DateTimeFormatter: provides 3 kinds of formatters to print a date/time value:
The standard formatters are mostly intended for machine-readable timestamps. To present date and times to human readers, use a local-specific formatter. 4 style: SHORT, MEDIUM, LONG, and FULL, for both date and time.
Locale-Specific Formatting Styles
Style
Date
Time
SHORT
7/16/69
9:32 AM
MEDIUM
Jul 16, 1969
9:32:00 AM
LONG
July 16, 1969
9:32:00 AM EDT
FULL
Wednesday, July 16, 1969
9:32:00 AM EDT
The static mehods ofLocalizedDate, ofLocalizedTime, and ofLocalizedDateTime craete such a formatter.
String formatted = formatter.format(apollo1Launch); // July 16, 1969 9:32:00 AM EDT
The java.time.format.DateTimeFormatter class is intended as a replacement for java.util.DateFormat. If you need an instance of the latter for backwards compatibility, call formatter.toFormat().
Finally, you can roll your own date format by specifying a pattern.
The first call uses the standard ISO_LOCAL_DATE formatter, the second one a custom formatter.
Interoperating with Legacy Code
Instant is a close analog to java.util.Date. Date has 2 added methods: 1. toInstant: converts a Date to an Instant and 2. from: converts in the other direction.
ZonedDateTime is a close analog to java.util.GregorianCalendar. GregorianCalendar has gained conversion methods too: 1. toZonedDateTime: converts a GregorianCalendar to a ZonedDateTime and 2. from: converts in the other direction.
Conversions between java.time Classes and Legacy Classes
Classes
To Legacy Class
From Legacy Class
Instant <-> java.util.Date
Date.from(instant)
date.toInstant()
ZonedDateTime <-> java.util.GregorianCalendar
GregorianCalendar.from(zonedDateTime)
cal.toZonedDateTime()
Instant <-> java.sql.Timestamp
TimeStamp.from(instant)
timestamp.toInstant()
LocalDateTime <-> java.sql.Timestamp
Timestamp.valueOf(localDateTime)
timestamp.toLocalDateTime()
LocalDate <-> java.sql.Date
Date.valueOf(localDate)
date.toLocalDate()
LocalTime <-> java.sql.Time
Time.valueOf(localTime)
time.toLocalTime()
DateTimeFormatter <-> java.text.DateFormat
formatter.toFormat()
None
java.util.TimeZone <-> ZoneId
Timezone.getTimezone(id)
timeZone.toZoneId()
]]>
<h1 id="Chapter-5-The-New-Date-and-Time-API"><a href="#Chapter-5-The-New-Date-and-Time-API" class="headerlink" title="Chapter 5 The New Date
Java SE 8 For the Really Impatient, Note 7http://blog.kiyanpro.com/2016/03/24/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-7/2016-03-24T22:29:00.000Z2017-07-04T19:34:24.000ZChapter 4 JavaFx is skipped for now.
Chapter 5 The New Date and Time API
Learn what makes time computations so vexing, and how the new Data and Time API solves these issues.
Key points:
All java.time objects are immutable
All Instant is a point on the time line (similar to Date)
In Java time, each day has exactly 86,400 seconds (i.e, no leap seconds)
A Duration is the difference between two instants
LocalDateTime has no time zone information
TemporalAdjuster methods handle common calendar computations, such as finding the first Tuesday of a month
ZonedDateTime is a point in time in a given time zone (similar to GregorianCalendar)
Use a Period, not a Duration, when advancing zoned time, in order to account for daylight savings time changes
Use DateTimeFormatter to format and parse dates and times
The Time Line
The Java Date and Time API specification requires that Java uses a time scale that
Has 86,400 seconds per day
Exactly matches the official time at noon each day
Closely matches it elsewhere, in a precisely defined way
Instant: represents a point on the time line. Instant.MIN: go back as far as a billion years. Instant.MAX: December 31 of the year 1,000,000,000 Instant.now(): gives the current instant You can compare two instants with the equals and compareTo methods in the usual way, so you can use instants as timestamps.
Duration.between: find out the difference between two instants
Duration: the amount of time between 2 instants. You can use toNanos, toMillis, toSeconds, toMinutes, toHours, toDays to get the length of a Duration.
Durations require more than a long for their internal storage. The number of seconds is stored in a long, and the number of nanoseconds in an additional int.
Method
Description
plus, minus
Adds a duration to, or subtracts a duration from, this Instant or Duration
Subtracts a number of the given time units from this Instant or Duration
multipliedBy, dividedBy, negated
Returns a duration that is obtained by multiplying or dividing this Duration by a given long, or by -1. Note that you can scale only durations, not instants
isZero, isNegative
Checks whether this Duration is zero or negative.
It takes almost 300 years of nanoseconds to overflow a long.
If you want to check whether an algorithm is ten times faster than another
// or timeElapsed.toNanos() * 10 < timeElapsed2.toNanos()
The Instant and Duration classes are immutable, and all methods, such as multipliedBy or minus, return new instance.
Local Dates
Human time: local date/time and zoned time.
Local date/time has a date and/or time of day, but no associated time zone information.
Do not use zoned time unless you really want to represent absolute time instances. Birthdays, holidays, shecdule times and so on are best represented as local dates or times.
LocalDate: is a date, with a year, month, and day of the month. Construct one with now or of static methods.
Period: the difference between two local dates, which expresses a number of elapsed years, months, or days. You can call birthday.plus(Period.ofYears(1)) to get the birthday of next year. Or birthday.plusYears(1). But birthday.plus(Duration.ofDays(365)) won’t be correct in a leap year.
until: yields the difference between 2 local dates.
1
independenceDay.until(christmas); // 5 months and 21 days
To find the number of days, use
1
independenceDay.until(christmas, ChronoUnit.DAYS); // 174 days
Some methods could potentially create nonexistent dates. Adding one month to January 31 should not yield February 31. Instead of throwing an exception, these meethods return the last valid day of month.
1
2
3
// yield Feb. 29, 2016
LocalDate.of(2016, 1, 31).plusMonths(1);
LocalDate.of(2016, 3, 31).minusMonths(1);
getDayOfWeek: yields the weekday, as a value of the DayOfWeek enumeration. DayOfWeek.MONDAY has the numerical value 1, and DayOfWeek.SUNDAY has the value 7.
DayOfWeek enumeration has convenience methods plus and minus to compute weekdays modulo 7. DayOfWeek.SATURDAY.plus(3) yields DayOfWeek.TUESDAY.
Different from LocalDate, Sunday has value 1 and Saturday has value 7 in java.util.Calendar.
MonthDay, YearMonth and Year are to describe partial dates in addition to LocalDate. December 25 can be represented as a MonthDay.
]]>
<p>Chapter 4 JavaFx is skipped for now. </p>
<h1 id="Chapter-5-The-New-Date-and-Time-API"><a href="#Chapter-5-The-New-Date-and-Time-API" cla
Java SE 8 For the Really Impatient, Note 6http://blog.kiyanpro.com/2016/03/23/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-6/2016-03-23T22:25:54.000Z2017-07-04T19:34:24.000ZChapter 3 Programming with Lambdas
Returning Functions
Consider methods whose return type is a functional interface.
The function(functional interface instance) can be passed to another method that expects such an interface.
You can write a method that yields a comparator for your needs, then pass to Arrays.sort(values, comparatorGenerator(customization arguments)).
Composition
Using two transformations is not very efficient. We need to store intermediate results. It would be better if we could compose the operations and then apply the composite operation to each pixel.
WritableImage out = new WritableImage(width, height);
for (int x = 0; x < width; x++)
for (int y = 0; y < height; y++) {
Color c = in.getPixelReader().getColor(x, y);
for (UnaryOperator<Color> f : pendingOperations) c = f.apply(c);
out.getPixelWriter().setColor(x, y, c);
}
}
Parallelizing Operations
When expressing operations as functional interfaces, the caller gives up control over the processing details, as long as the correct result is achieved. We can make use of concurrency. E.g, in image processing we can split the image into multiple strips and process each strip separately.
An example on concurrent image transformation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
publicstatic Color[][] parallelTransform(Color[][] in, UnaryOperator<Color> f) {
int n = Runtime.getRuntime().availableProcessors();
int height = in.length;
int width = in[0].length;
Color[][] out = new Color[height][width];
try {
ExecutorService pool = Executors.newCacheThreadPool();
for (int i = 0; i < n; i++) {
int fromY = i * height / n;
int toY = (i + 1) * height / n;
pool.submit(() -> {
for (int x = 0; x < width; x++)
for (int y = fromY; y < toY; y++)
out[y][x] = f.apply(int[y][x]);
});
pool.shutdown();
pool.awaitTermination(1, TimeUnit.HOURS);
}
} catch (InterruptedException ex) {
ex.printStackTrace();
}
return out;
}
In general, when you are given an object of a functional interface and you need to invoke it many times, ask yourself whether you can take advantage of concurrency.
Dealing with Exceptions
When an exception is thrown in a lambda expression, it is propagated to the caller.
If first.run() throws an exception, the thread is terminated, and second is never run. However, the doInOrderAsync returns right away and does the work in a separate thread, so it’s not possible to have the method rethrow the exception.
In this situation, it is good to supply a handler.
Alternatively, we could make second a Biconsumer<T, Throwable> and have it deal with the exception from first.
It’s often inconvenient that methods is functional interfaces don’t allow check exception. You methods can accept functional interfaces whose methods allow checked exceptions, such as Callable<T> instead of Supplier<T>. A Callable<T> has a method that is declared as T call() throws Exception.
If you want an equivalent for a Consumer or a Function, you have to create it yourself.
unchecked(() -> new String(Files.readAllBytes(Paths.get("/etc/passwd")), StandardCharsets.UTF_8))
to a Supplier<String>, even though the readAllBytes method throws an IOException.
This method cannot generate a Consumer<T> or a Function<T, U>. You would need to implement a variabtion of unchecked for each functional interface.
Lambdas and Generics
You cannot construct a generic array at runtime. E.g, the toArray() method of Collection<T> and Stream<T> cannot call T[] result = new T[n]. Therefore, these methods return Object[] arrays.
With lambdas, we can pass the constructor.
1
String[] result = words.toArray(String[]::new);
When you implement such a method, the constructor expression is an IntFunction<T[]>, since the size of the array is passed to the constructor. In your code, you call T[] result = constr.apply(n).
T of List<T> is invariant. A method can decide to accept a List<? extends Person> if it only reads from the list. Then you can pass either a List<Person> or a List<Employee>. Or it can accept a List<? super Employee> if it only writes to the list.
In general, reading is covariant(subtypes are okay) and writing is contravariant(supertypes are okay).
As the implementor of a method that accepts lambda expressions with generic types, you simply add ? super to any argument type that is not also a return type, and ? extends to any return type that is not also an argumetn type.
Monadic Operations
A design pattern for providing compositions funtions that yield values from generic types.
Consider a generic type G<T>, such as List<T>, Optional<T>, Future<T>. Also consider a function T -> U, or a Function<T, U> object. It often makes sense to apply this function to a G<T>.
Generally, when you design a type G<T> and a function T -> U, think whether it makes sense to define a map that yields a G<U>. Then generalize to functions T -> G<U> and, if appropriate, provide flatMap.
]]>
<h1 id="Chapter-3-Programming-with-Lambdas"><a href="#Chapter-3-Programming-with-Lambdas" class="headerlink" title="Chapter 3 Programming wi
Java SE 8 For the Really Impatient, Note 5http://blog.kiyanpro.com/2016/03/22/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-5/2016-03-22T20:44:25.000Z2017-07-04T19:34:24.000ZChapter 3 Programming with Lambdas
Learn how to create your own libraries that make use of lambda expressions and functional interfaces.
Key points:
Main reason for using lambda expression: defer the execution of the code until an appropriate time
When a lambda expression is executed, make sure to provide any required data as inputs
Choose one of the existing functional interfaces if you can
It’s often useful to write methods that return an instance of a functional interface
When you work with transformations, consider how you can compose them
To compose transformations lazily, you need to keep a list of all pending transformations and apply them in the end
If you need to apply a lambda many times, you often have a chance to split up the work into subtasks that execute concurrently
Think what should happen when you work with a lambda expression that throws an exception
When working with generic functional interfaces, use ? super wildcards for argument types, ? extends wildcards for return types
When working with generic types that can be transformed by functions, consider supplying map and flatMap
Deferred Execution
The point of all lambdas is deferred execution. Reasons for executing code later:
Running the code in a separate thread
Running the code multiple times
Running the code at the right point in an algorithm(e.g, the comparison operation in sorting)
Running the code when something happens(a buttom was clicked, data has arrived, etc.)
Running the code only when necessary
Suppose you log an event:
1
logger.info("x: " + x + ", y: " + y);
If the log level is set to suppress INFO messages, the message string still gets computed and passed to the method, then it would be thrown away. It would be nicer if the string concatenation only happened when necessary.
Running code only when necessary is a use case for lambdas. Write a method that:
The info method, as well as other logging methods, now have variants that accept a Supplier<String>. You can directly call logger.info(() -> "x: " + x + ", y: " + y);
publicstaticvoidrepeat(int n, IntConsumer action){
for (int i = 0; i < n; i++) action.accept(i);
}
We tell the action in which iteration it occurs. The action needs to capture that input in a parameter.
1
repeat(10, i -> System.out.println("Countdown: " + (9 - i)));
An event handler button.setOnAction(event -> action). The event object carries information that the action may need.
In general, you want to design your algorithm so that it passes any required information as arguments. However, if these arguments are rarely needed, consider supplying a second version that doesn’t force users into accepting unwanted arguments.
To specify a function that maps 2 strings into an integer, you use Function2<String, String, Integer> or (String, String) -> int.
In Java, you instead declare the intent of the function, using a functional interface such as Comparator<String>.
In the theory of programming languages this is called nominal typing.
If you want to accept “any function” without particular semantics, there are some options.
Functional Interfaces
Parameter Types
Return Type
Abstract Method Name
Description
Other Methods
Runnable
none
void
run
Runs an action without arguments or return value
Supplier<T>
none
T
get
Supplies a value of type T
Consumer<T>
T
void
accept
Consumes a value of type T
andThen
BiConsumer<T, U>
T, U
void
accept
Consumes values of types T and U
andThen
Function<T, R>
T
R
apply
A function with argument of type T
compose andThen identity
BiFunction<T, U, R>
T, U
R
apply
A function with arguments of types T and U
andThen
UnaryOperator<T>
T
T
apply
A unary operator on the type T
compose andThen identity
BinaryOperator<T, T>
T, T
T
apply
A binary operator of the type T
andThen maxBy minBy
Predicate<T>
T
boolean
test
A Boolean-valued function
and or negate isEqual
Bipredicate<T, U>
T, U
boolean
test
A Boolean-valued function with 2 arguments
and, or negate
Most of the standard functional interfaces have nonabstract methods for producing or combining functions. Predicate.isEqual(a) is the same as a::equals, provided a is not null. And there are default methods and, or, negate for combining predicates. E.g, Predicate.isEqual(a).or(Predicate.isEqual(b)) is the same as x -> a.equals(x) || b.equals(x).
publicstatic Image transform(Image in, UnaryOperator<Color> f){
int width = (int) in.getWidth();
int height = (int) in.getHeight();
WritableImage out = new WritableImage(width, height);
for (int x = 0; x < width; x++)
for (int y = 0; y < height: y++)
out.getPixelWriter().setColor(x, y, f.apply(in.getPixelReader().getColor(x, y)));
return out;
}
No need for a ColorTransformer interface.
Functional Interfaces for Primitive Types
Functional Interface
Parameter Types
Return Type
Abstract Method Name
BooleanSupplier
none
boolean
getAsBoolean
PSupplier
none
P
getAsP
PConsumer
P
void
accept
ObjPConsumer
T, p
void
accept
PFunction<T>
p
T
apply
PToQFunction
p
q
applyAsQ
ToPFunction<T>
T
p
applyAsP
ToPBiFunction<T, U>
T, U
p
applyAsP
PUnaryOperator
p
p
applyAsP
PBinaryOperator
p, p
p
applyAsP
PPredicate
p
boolean
test
p, q is int, long, double P, Q is Int, Long, Double
Supply your own functional interface. (int, int, Color) -> Color
1
2
3
4
@FunctionalInterface
publicinterfaceColorTransformer{
Color apply(int x, int y, Color colorAtXY);
}
apply is used for majority of standard functional interfaces.
]]>
<h1 id="Chapter-3-Programming-with-Lambdas"><a href="#Chapter-3-Programming-with-Lambdas" class="headerlink" title="Chapter 3 Programming wi
Java SE 8 For the Really Impatient, Note 4http://blog.kiyanpro.com/2016/03/21/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-4/2016-03-21T21:12:12.000Z2017-07-04T19:34:24.000ZChapter 2 The Stream API
Grouping and Partioning
groupingBy: forms groups of values with the same characteristic
When the classifier function is a predicate function(that is, a function returning a boolean value), the stream elements are partitioned into 2 list: those where the function returns true and the complement. In this case it’s more efficient to use partitioningBy instead.
If you call the groupingByConcurrent method, you get a concurrent map that, when used with a parallel stream, is concurrently populated. Analogous to toConcurrentMap.
If you want sets instead of list, use downstream collector Collectors.toSet.
Only use downstream collectors in connection with groupingBy or partitioningBy to avoid convoluted expressions. Otherwise, simply use methods like map, reduce, count, max or min directly on streams.
Primitive Type Streams
Wrap each integer into a wrapper object like Stream<Integer> is inefficient. Same for the other primitive types.
IntStream, LongStream, DoubleStream can store primitive values directly. For the other primitives: IntStream: store short, char, byte and boolean DoubleStream: float
Create an IntStream: use IntStream.of or Arrays.stream
1
2
3
IntStream stream = IntStream.of(1, 1, 2, 3 ,5);
// or
stream = Arrays.stream(values, from, to); // values is an int[] array
IntStream and LongStream have static methods range and rangeClosed that generate integer ranges with step size one
IntStream zeroToHundred = IntStream.rangeClose(0, 100); // Upperbound included
The CharSequence interface has methods codePoints and chars that yield an IntStream of the Unicode codes of the characters or of the code units in the UTF-16 encoding
1
2
String sentence = "\uD835\uDD46 is the set of octonions";
Differences between primitive type streams and object streams:
toArray returns primitive type arrays
Methods that yield an optional result return an OptionalInt, OptionalLong or OptionalDouble. They have methods getAsInt, getAsLong and getAsDouble instead of get.
sum, average, max, min are defined.
The summaryStatistics method yield an object of type IntSummaryStatistics, LongSummaryStatistics, or DoubleSummaryStatistics
The Random class has methods ints, longs and doubles that return primitive type streams of random numbers
Parallel Streams
Must have a parallel stream to parallelize bulk operations.
By default, stream operations create sequential streams, except for Collection.parallelStream().
parallel: converts any sequential stream into a parallel one
The operations are stateless and can be executed in arbitrary order. A bad example, something you cannot do
1
2
3
4
5
int[] shortWords = newint[12];
words.parallel().forEach(
s -> { if (s.length() < 12) shortWords[s.length()]++; }
);
System.out.println(Arrays.toString(shortWords));
The function passed to forEach runs concurrently in multiple threads, updating a shared array. Race condition!
Ensure that any functions you pass to parallel stream operations are threadsafe. You can use an array of AtomicInteger objects. Or you can simply use the facilities of streams library and group strings by length.
By default, streams that arise from ordered collections (arrays and lists), from ranges, generators, and iterators, or from calling Stream.sorted, are ordered.
Some operations can be more effectively parallelized when the ordering requirement is dropped. Stream.unordered means there will be no ordering. Stream.distinct can benefit from it because on an ordered stream, distinct retains the first of all equal elements.That impedes parallelization. limit can be speeded up if you just want any n elements from a stream and don’t care which ones you get.
Merging map is expensive. The Collectors.groupingByConcurrent method uses a shared concurrent map. The collector is unordered already.
1
2
3
Map<String, List<String>> result = cities.parallel().collect(
Collectors.groupingByConcurrent(City::getState) // values aren't collected in stream order
);
Noninterference Do not modify the collection that is backing a stream while carrying out a stream operation, even if it’s threadsafe. Remember that streams don’t collect their own data - the data is always in a separate collection.
Since intermediate stream operations are lazy, it’s possible to mutate the collection up to the point when the terminal operation executes.
1
2
3
4
List<String> wordList = ...;
Stream<String> words = wordList.stream();
wordsList.add("END"); // OK
long n = words.distinct().count();
Bad example updating collection during operation
1
2
Stream<String> words = wordList.stream();
words.forEach(s -> if (s.length() < 12)) wordList.remove(s)); // interference
Functional Interfaces
Predicate: an interface with one nondefault method returning a boolean value
A function with argument of type int, long, or double
Function<T, R>
T
R
A function with argument of type T
BiFunction<T, U, R>
T, U
R
A function with arguments of types T and U
UnaryOperator<T>
T
T
A unary operator on the type T
BinaryOperator<T>
T, T
T
A binary operator on the type T
]]>
<h1 id="Chapter-2-The-Stream-API"><a href="#Chapter-2-The-Stream-API" class="headerlink" title="Chapter 2 The Stream API"></a>Chapter 2 The
Java SE 8 For the Really Impatient, Note 3http://blog.kiyanpro.com/2016/03/17/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-3/2016-03-18T00:05:32.000Z2017-07-04T19:34:24.000ZChapter 2 The Stream API
Simple Reductions
reductions: reduces the stream to a value. terminal operation: the stream ceases to be usable.
List of reductions:
count
max
min
findFirst
findAny
anyMatch
allMatch
noneMatch
count: returns the number of elements of the stream.
max: returns the largest value. min: returns the smallest value. These methods return an Optional<T> value that either wraps the answer or indicates that there is none(empty stream).
1
2
3
4
// get the maximum of a stream
Optional<String> largest = words.max(String::compareToIgnoreCase);
if (largest.isPresent())
System.out.println("largest: " + largest.get());
findFirst: returns the first value in a nonempty collection. Useful when combined with filter.
findAny: returns any match. Effective when you parallelize the stream since the first match in any of the examined segments will complete the computation.
allMatch: return true if all elements match a predicate. noneMatch: return true if no elements match a predicate. These methods always examine the entire stream, but they still benefit from being run in parallel.
The Optional Type
Either a wrapper for an object of type T or for no object. Intended as a safer alternative than a reference of type T that returns to an obejct or null.
Working with Optional Values
get: gets the wrapped element if it exists, or throw a NoSuchElementException if it doesn’t isPresent: reports whether an Optional<T> object has a value
1
2
3
Optional<T> optionalValue = ...;
if (optionalValue.isPresent())
optionalValue.get().someMethod();
No easier than if (value != null) value.someMethod();
The key to using Optional effectively is to use a method that either consumes the correct value or produces an alternative. ifPresent: accepts a function. If the optional value exists, it is passed to that function. Otherwise, nothing happens.
1
2
3
4
optionalValue.ifPresent(v -> Process v);
// add value to a set
optionalValue.ifPresent(v -> results.add(v));
optionalValue.ifPresent(results::add);
No value is returned in ifPresent. Instead, map returns the result.
added has one of 3 values: true or false wrapped into an Optional, if optionalValue was present, or an empty optional otherwise.
orElse: sets a default when there is no match
1
String result = optionalString.orElse("");
1
2
// invoke code to compute default
String result = optionalString.orElseGet(() -> System.getProperty("user.dir"));
1
2
// throw an exception if there is no value
String result = optionalString.orElseThrow(NoSuchElementException::new);
Creating Optional Values
Optional.of(result) and Optional.empty() are static methods to create Optionals.
1
2
3
publicstatic Optional<Double> inverse(Double x){
return x == 0 ? Optional.empty() : Optional.of(1 / x);
}
ofNullable: a bridge from the use of null values to optional values. Returns Optional.of(obj) if obj is not null, otherwise, Optional.empty()
Composing Optional Value Functions with flatMap
Suppose you have a method f yielding an Optional<T>, and the target type T has a method g yielding an Optional<U>. If they were normal methods, you could compose them by call s.f().g(). This doesn’t work for Optionals because s.f() has type Optional<T>, not T.
1
Optional<U> result = s.f().flatMap(T::g);
If s.f() is present, then g is applied to it. Otherwise, an empty Optional<U> is returned.
Chaining flatMap
1
Optional<Double> result = Optional.of(-4.0).flatMap(Test::inverse).flatMap(Test::squareRoot);
If either the inverse method or the squareRoot returns Optional.empty(), the result is empty.
The flatMap method of Optional works in the same way if you consider an optional value to be a stream of size zero or one.
Reduction Operations
If you want to compute a sum, or combine the elements of a stream to a result in another way, use one of the reduce methods.
The reduce method below computes v0+v1+v2+…
1
2
Stream<Integer> values = ...;
Optional<Integer> sum = values.reduce((x, y) -> x + y); // or values.reduce(Integer::sum);
The method returns an Optional because there is no valid result if the stream is empty.
In general, if the reduce method has a reduction operation op, the reduction yields v0op v1op v2op …, where we write viop vi+1 for the function call op(vi, vi+1) The operation should be associative: it should not matter in which order you combine the elements.
Useful associative operations: sum, product, string concatenation, maximum, minimum, set union and intersection.
subtraction is not associative.
identity: e such that e op x = x. E.g, 0 is the identity for addition.
1
2
Stream<Integer> values = ...;
Integer sum = values.reduce(0, (x, y) -> x + y);
The identity value is returned if the stream is empty, and you no longer need to deal with the Optional class.
Simple form of reduce requires a function (T, T) -> T, with the same types for the arguments and the result.
If you want to calculate all lengths in a stream of strings, you need to use accumulator.
1
2
3
int result = words.reduce(0,
(total, word) -> total + word.length(), // accumulator is called repeatedly forming the cumulative total
Easier to map to a stream of numbers and use one of its methods to compute sum, max or min.
1
words.mapToInt(String::length).sum(); // simpler and more efficient
Collecting Results
Just want to look at the result.
iterator: yields an old fashioned iterator that you can use to visit the elements. toArray: get an array of the stream elements.
stream.toArray() returns an Object[] array. If you want an array of the correct type, pass in the array constructor:
1
String[] result = words.toArray(String[]::new);
collect: takes 3 arguments
A supplier to make new instances of the target object, e.g, a constructor for hash set
An accumulator that adds an element to the target, e.g, an add method
A combiner that merges 2 objects into 1, such as addAll
1
HashSet<String> result = stream.collect(HashSet::new, HashSet::add, HashSet:addAll);
The target object need not to be a collection. It could be a StringBuilder or an object that tracks a count and a sum.
Collector: convenient interface Collectors: class with factory methods for common collectors
1
2
3
// collect a stream into a list or set
List<String> list = stream.collect(Collectors.toList());
Set<String> set = stream.collect(Collectors.toSet());
Control which kind of set you get
1
TreeSet<String> result = stream.collect(Collectors.toCollection(TreeSet::new));
Collect all strings in a stream by concatenating them
1
String result = stream.collect(Collectors.joining());
Add delimiter between elements
1
String result = stream.collect(Collectors.joining(","));
Convert non-string to string first
1
String result = stream.map(Object::toString).collect(Collectors.joining(","));
If you want to reduce the stream results to a sum, average, maximum, or minimum, use one of the methods summarizing(Int|Long|Double). These methods take a function that maps the stream objects to a number and yield a result of type (Int|Long|Double)SummaryStatistics, with methods for obtaining the sum, average, maximum and minimum.
forEach: just want to print them or put them in a database
1
stream.forEach(System.out::println);
On a parallel stream, you must ensure that the function can be executed concurrently.
forEachOrdered: execute in stream order. No parallelism benefits anymore.
forEach and forEachOrdered are terminal operations. If you want to continue using the stream, use peek instead.
Collecting into Maps
Suppose you want to collect the elements in Stream<Person> into a map so that you can later look up people by their id. Collectors.toMap: has 2 function arguments that produce the map keys and values
If there is more than one element with the same key, the collector will throw an IllegalStateException. Supply a third function argument that determines the value for the key, given the existing and the new value.
Construct a map that contains, for each language in the available locales, as key its name in your default locale(such as “German”), and as value its localized name(such as “Deutsch”).
For each of the toMap methods, there is an equivalent toConcurrentMap method that yields a concurrent map. A single concurrent map is used in the parallel collection process. When used with a parallel stream, a shared map is more efficient than merging maps, but of course, you give up ordering.
]]>
<h1 id="Chapter-2-The-Stream-API"><a href="#Chapter-2-The-Stream-API" class="headerlink" title="Chapter 2 The Stream API"></a>Chapter 2 The
Java SE 8 For the Really Impatient, Note 2http://blog.kiyanpro.com/2016/03/16/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-2/2016-03-16T22:31:28.000Z2017-07-04T19:34:24.000ZChapter 2 The Stream API
Processing collections of values and specifying what you want to have done, leaving the scheduling of operations to the implementation. E.g, compute the average of the values of a certain method.
Key points:
Iterators imply a specific traversal strategy and prohibit efficient concurrent execution.
You can create streams from collections, arrays, generators, or iterators.
Use filter to select elements and map to transform elements.
Other operations for transforming streams include limit, distinct, and sorted.
To obtain a result from a stream, use a reduction operator such as count, max, min, findFirst, or findAny. Some of these methods return an Optional value.
The Optional type is intended as a safe alternative to working with null values. To use it safely, take advantage of the ifPresent and orElse methods.
You can collect stream results in collections, arrays, strings or maps.
The groupingBy and partitioningBy methods of the Collectors class allow you to split the contents of a stream into groups, and to obtain a result for each group.
There are specialized streams for the primitive types, int, long, and double.
When you work with parallel streams, be sure to avoid side effects, and consider giving up ordering constraints.
You need to be familiar with a small number of functional interfaces in order to use the stream library.
From Iteration to Stream Operations
Usually iterate over collection’s elements and do some work with each of them.
1
long count = words.stream().filter(w -> w.length() > 12).count();
The stream method yields a stream for the words list. The filter method returns another stream that contains only the words of length greater than twelve. The count method reduces that stream to a result.
Differences between stream and collections
Stream does not store its elements.
Stream operations don’t mutate source. They return new streams that hold the reuslt.
Stream operations are lazy when possible. Not executed until their result is needed.
Easily parallelized by changing stream to parallelStream
1
long count = words.parallelStream().filter(w -> w.length() > 12).count();
What. not how principle: we describe what needs to be done, don’t specify in which order, or in which thread, this should happen.
Setup a pipeline of operations in 3 stages:
Create a stream.
Specify intermediate operations for transforming the initial stream into others
Apply a terminal operation to produce a result. Afterwards, the stream can no longer be used.
Stream operations are not executed on the elements in the order in which they are invoked on the streams. Nothing happens until count is called. When the count method asks for the first element, then the filter method starts requesting elements, until it finds one that has length > 12.
Stream Creation
Turn any collection in to a stream with the stream method that Java8 added to the Collection interface
Use the static Stream.of method for arrays
1
Stream<String> words = Stream.of(contents.split("[\\P{L}+"))
The of method has a varargs parameters
1
Stream<String> song = Stream.of("gently", "down", "the", "stream");
Use Array.stream(array, from, to) to make stream from a part of an array.
Use the static Stream.empty method to make a stream with no elements
1
Stream<String> silence = Stream.empty();
2 interfaces for making infinite streams: generate takes a function with no arguments(or, an object of the Supplier<T> interface). Whenever a stream value is needed, that function is called to produce a value
1
2
3
Stream<String> echos = Stream.generate(() -> "Echo"); // get a stream of constant values
Stream<Double> randoms = Stream.generate(Math::random); // get a stream of random numbers
iterate takes a seed value and a function(a UnaryOperator<T>), and repeatedly applies the function to the previous result.
1
Stream<BigInteger> integers = Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE));
Pattern class has a method splitAsStream that splits a CharSequence by a regular expression.
1
2
// split a string into words
Stream<String> words = Pattern.compile("[\\P{L}+").splitAsStream(contents);
File.lines method returns a Stream of all lines in a file.
1
2
3
try (Stream<String> lines = Files.lines(path)) {
// Do something with lines
}
The stream and the underlying file with it will be closed when the try block exits normally or through an exception.
The filter.map and flatMap Methods
filter: yields a new stream with all elements that match a certain condition
1
2
3
4
// transform a stream of strings into another stream contaning only long words
peek: yields another stream with the same elements as the original, but a function is invoked every time an element is retrieved.
1
2
3
Obejct[] powers = Stream.iterate(1.0, p -> p * 2)
.peek(e -> System.out.println("Fetching " + e))
.limit(20).toArray();
This way you can verify that the infinite stream returned by iterate is processed lazily.
Stateful Transformations
distinct: yields elements from the original stream, in the same order, except that duplicates are suppressed. The stream must obviously remember the elements that it has already seen.
sorted: must see the entire stream and sort it before it can give out any elements. You can’t sort an infinite stream. One for Comparable elements, the other accepts a Comparator. Useful when the sorting process is a part of a stream pipeline.
The Collections.sort method sorts a collection in place, whereas Stream.sorted returns a new sorted stream.
]]>
<h1 id="Chapter-2-The-Stream-API"><a href="#Chapter-2-The-Stream-API" class="headerlink" title="Chapter 2 The Stream API"></a>Chapter 2 The
Java SE 8 For the Really Impatient, Note 1http://blog.kiyanpro.com/2016/03/15/java/Java8ForTheReallyImpatient/Java-SE-8-For-the-Really-Impatient-Note-1/2016-03-15T22:12:44.000Z2017-07-04T19:34:24.000ZChapter 1 Lambda Expressions
Why
A block of code was passed to someone - a thread pool, a sort method, or a button. The code was called at some later time. How to work with blocks of code directly in Java? Lambda expression.
Use Integer.compare(x, y) instead of x - y to compare x and y since that computation can overflow.
Syntax
Java is a strong typed language, we must specify type. parameters, the -> arrow, and an expression
Arrays.sort method receives an object of some class that implements Comparator<String>. Invoking the compare method on that object executes the body of the lambda expression.
More efficient, easier to read, short and simple
1
2
button.setOnAction(event ->
System.out.println("Thanks for clicking!"));
You cannot assign lambda to an object. Only thing you can do is conversion to functional interface.
There are generic functional interfaces in java.util.function package. BiFunction<T, U, R> describes functions with parameter types T and U and return type R. You can save lambda in a variable of that type.
Tag any functional interface with @FunctionalInterface annotation. Compiler will check that the annotated entity is an interface with a single abstract method. And the Javadoc page includes a statement that your interface is a functional interface.
If the body of a lambda expression may throw a checked exception, that exception needs to be declared in the abstract method of the target interface.
1
2
3
4
Runnable sleeper = () -> {
System.out.println("Zzz");
Thread.sleep(1000); // Error: Thread.sleep can throw a checked InterruptedException
}
Runnable.run cannot throw any exception. How to fix?
catch the exception in the body of the lambda expression
assign the lambda expression to an interface whose single abstract method can throw the exception. e.g, the call method of the Callable interface
1
2
3
4
5
Callable<Void> call = () -> {
System.out.println("Zzz");
Thread.sleep(1000);
returnnull; // add this statement
}
Method References
When there is already a method that carries out exactly the action that you’d like to pass on to some other code.
1
button.setOnAction(System.out::println)// just pass the println method to the setOnAction method
Equivalent to x -> System.out.println(x)
1
Arrays.sort(strings, String::compareToIgnoreCase)
The :: operator separates the method name from the name of an object or class
object::instanceMethod
Class::staticMethod
Class::instanceMethod
The first two cases: the method reference is equivalent to a lambda expression that supplies the parameters of the method.
The third case: the first parameter becomes the target of the method. String::compareToIgnoreCase is the same as (x, y) -> x.compareToIgnoreCase(y)
Invoke a method of an enclosing class or its superclass. this::equals is the same as x -> this.equals(x) super::instanceMethod uses this as the target and invokes the superclass version of the given method.
1
2
3
4
5
6
7
8
9
10
11
12
classGreeter{
publicvoidgreet(){
System.out.printlin("Hello, world!");
}
}
classConcurrentGreeterextendsGreeter{
publicvoidgreet(){
Thread t = new Thread(super::greet);
t.start();
}
}
In an inner class, capture the this reference of an enclosing class as EnclosingClass.this::method or EnclosingClass.super::method
Constructor References
Just like method references, except that the name of method is new. Button::new is a reference to a Button constructor.
Which constructor depends on the context.
You can form constructor reference with array types. int[]::new is a constructor references with one parameter, the length of the array.
Obtain an array of the correct type instead of object
1
Button[] buttons = stream.toArray(Button[]::new)
Variable Scope
A lambda expression has 3 ingredients:
A block of code
Parameters
Values for the free variables, that is, the variables that are not parameters and not defined inside the code
These values have been captured by lambda expression. Technical term is closure. A lambda expression can capture the value of a variable in the enclosing scope.
In lambda expression, you can only reference variables whose value does not change.
1
2
3
4
5
6
7
8
9
10
publicstaticvoidrepeatMessage(String text, int count){
Mutating variables in a lambda expression is not threadsafe.
Trick to update a count in an enclosing local scope in lambda expression
1
2
int[] counter = newint[1];
button.setOnAction(event -> counter[0]++);
Still not threadsafe. Think twice before using this trick.
Cannot use same variable name as local variables.
this in lambda expression refers to the this parameter of the method that creates the lambda.
1
2
3
4
5
6
7
publicclassApplication{
publicvoiddoWork(){
Runnable runner = () -> { ...;
System.out.println(this.toString()); ... };
...
}
}
this.toString() calls the toString method of the Application object, not the runnable instance. The scope of the lambda expression is nested inside the doWork method, and this has the same meaning anywhere in that method.
Default Methods
In Java 8, the forEach method has been added to the Iterable interface, a superinterface of Collection.
A concrete class that implements the Person interface must provide an implementation of getId but it can choose to keep the implementation of getName or to override it.
Rules when conflict:
class wins
provide implementation if at least one has implemented the method
Static Methods in Interfaces
Do not need static methods in a companion class anymore.
Comparator class has a very useful static comparing method that accepts a “key extraction” function and yields a comparator that compares the extracted keys. To compare Person object by name
1
Comparator.comparing(Person::getName)
The same as (x, y) -> x.compareToIgnoreCase(y)
1
Comparator.comparing(String::length)
The same as (first, second) -> Integer.compare(first.length(), second.length())